SPAN: Spatial-Projection Alignment for Monocular 3D Object Detection

🏛️ 会议/期刊:CVPR / ICCV / ECCV
📅 发表年份:2026
💻 开源代码:GitHub 链接
📄 论文题目:SPAN: Spatial-Projection Alignment for Monocular 3D Object Detection
1. 文献背景与研究动机
背景与现状
单目3D目标检测(Monocular 3D Object Detection)是自动驾驶和机器人视觉中的核心任务,旨在仅通过单张RGB图像预测物体的3D边界框。
核心问题
目前主流的方法多采用解耦预测范式(Decoupled Prediction Paradigm):将3D边界框的回归任务拆分为多个独立的分支,分别预测中心点、深度、尺寸和旋转角。
-
痛点: 这种策略虽然简化了学习,但忽略了各几何属性之间的协同约束关系。
-
后果: 预测结果往往缺乏几何一致性(如3D框在投影回2D平面时与原物体不匹配),导致定位精度遇到瓶颈。
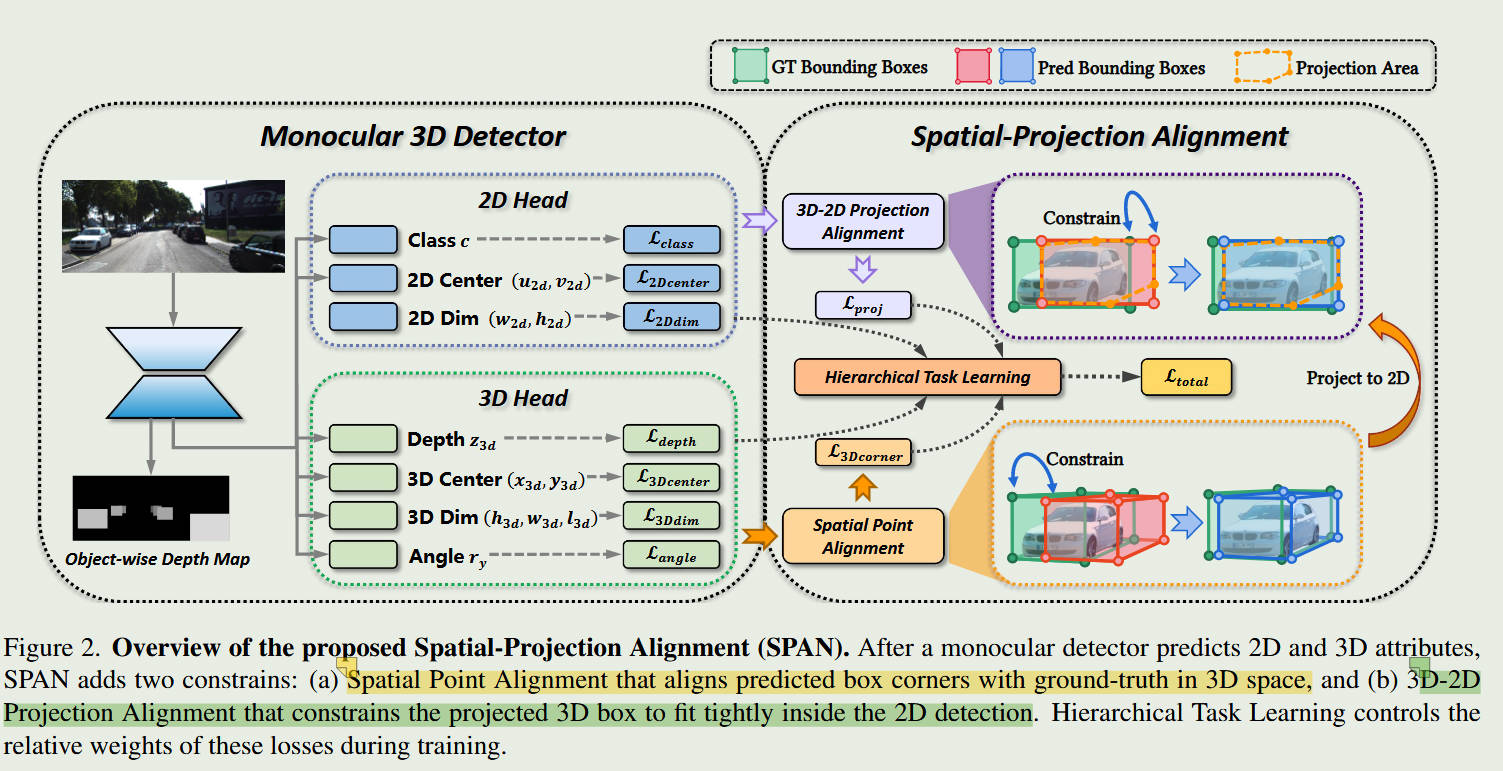
整体框架图
2. 核心技术:SPAN 框架
论文提出了 SPAN (Spatial-Projection Alignment),这是一种可插件式(Plug-and-play)的优化框架,核心包含两大对齐组件和一套训练策略。
(1) 空间点对齐 (Spatial Point Alignment)
-
原理: 强制预测的3D边界框与地面真值(Ground-truth)之间存在显式的全局空间约束。
-
作用: 纠正因解耦回归导致的“空间漂移”。它不是单独看深度或位置,而是将3D框作为一个整体,通过惩罚空间顶点的偏移来保证整体几何形状的正确性。
(2) 3D-2D 投影对齐 (3D-2D Projection Alignment)
-
原理: 确保3D框在投影到2D图像平面后,能紧密且准确地嵌套在其对应的2D检测框内。
-
通俗解释: 想象一个纸箱(3D框),你从相机视角看过去,它的轮廓应该刚好填满照片里的那个矩形(2D框)。如果投影出来的轮廓歪了或小了,说明3D参数(尤其是深度和角度)算错了。
(3) 分层任务学习 (Hierarchical Task Learning, HTL)
-
创新点: 针对训练初期参数波动剧烈、几何约束容易失效的问题,HTL 采取“先易后难”的策略。
-
逻辑: 随着3D属性预测趋于稳定,逐步增加空间-投影对齐损失的比重,防止早期的错误预测通过几何约束传播,从而确保训练的稳定性。
3. 主要发现与结论
-
显著提升: 实验证明,将 SPAN 集成到现有的 SOTA(先进)单目检测模型中,无需在推理阶段增加任何额外模块或计算开销,即可大幅提升 AP(平均精度)。
-
几何一致性: 定性分析显示,经过 SPAN 优化的模型生成的3D框在投影视觉上更加自然,解决了以往深度估算与视觉表现不符的问题。
-
普适性: 该框架表现出极强的通用性,能无缝适配多种主流的单目3D检测基准模型。
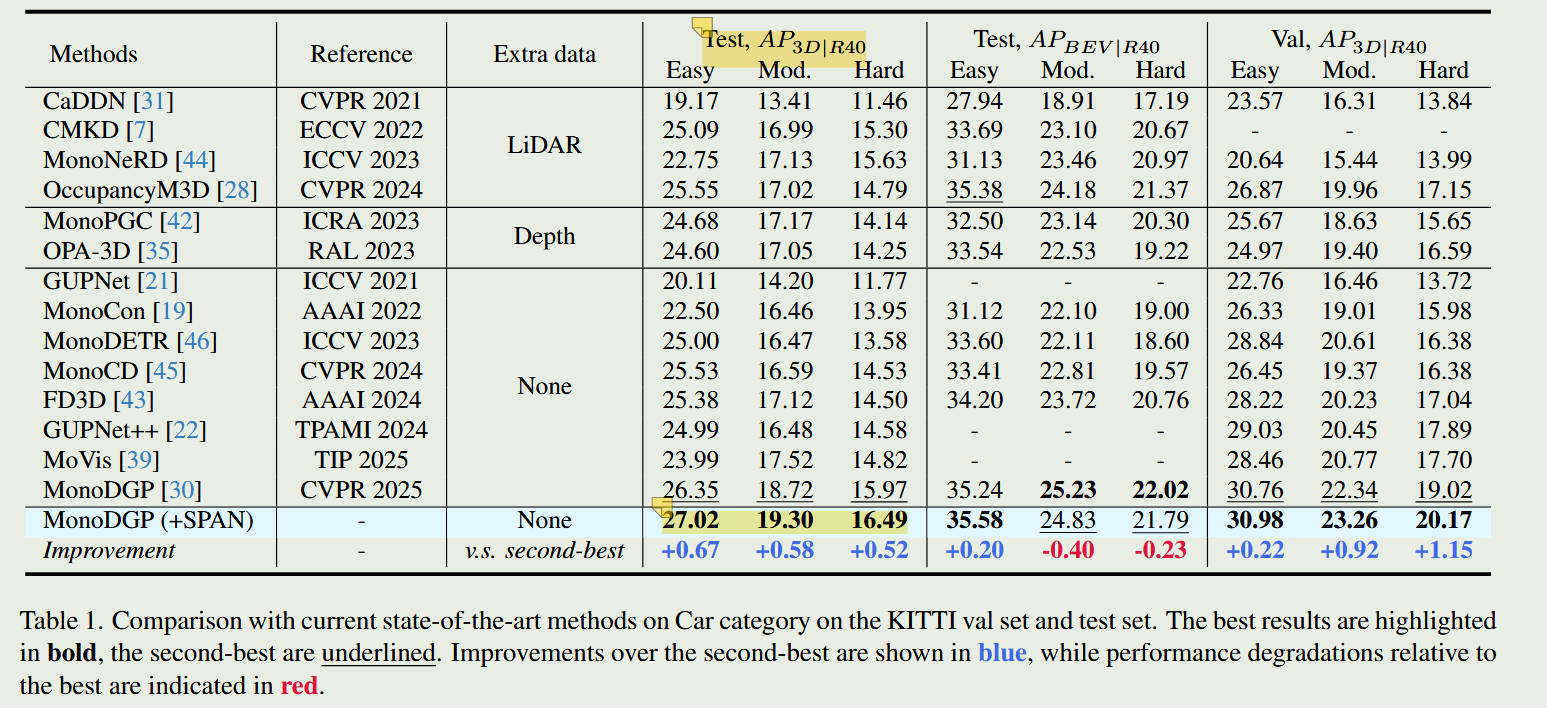
结果对比
4. 专家客观评价
优点
-
即插即用: 这是一个基于 Loss(损失函数)层面的优化方案,不改变模型前向计算结构,易于在工业界部署。
-
物理直觉强: 抓住了“投影一致性”这一单目视觉的核心几何矛盾,研究逻辑自洽。
-
训练稳健: HTL 策略有效解决了复杂几何约束在训练初期易引发梯度爆炸或不收敛的顽疾。
缺点/局限性
-
极度依赖2D质量: 投影对齐高度依赖2D检测框的精度,若2D检测受遮挡或光照影响较大,可能会误导3D参数的优化。
-
算力成本: 虽然推理无开销,但在训练阶段计算投影对齐(涉及矩阵运算和顶点变换)会增加一定的训练时长。
5. 后续研究方向
-
遮挡处理: 探索在物体被严重遮挡、2D框不完整的情况下,如何利用局部特征进行投影对齐。
-
多帧协同: 将 SPAN 的空间对齐扩展到视频序列中,利用时间连续性进一步平滑3D框的预测。
-
端到端协同: 考虑将 2D 检测器的预测不确定性引入 SPAN,实现动态权重的几何对齐。