Open Vocabulary Monocular 3D Object Detection

🏛️ 会议/期刊:3DV
📅 发表年份:2026
💻 开源代码:UVA-Computer-Vision-Lab/ovmono3d
📄 论文题目:Open Vocabulary Monocular 3D Object Detection
一、 背景、研究目的与核心问题
-
研究背景: 传统的单目 3D 目标检测(M3OD)模型都属于“闭集(Closed-set)”学习。这意味着模型只能检测训练集中预先定义好的那几种类别(例如 KITTI 数据集里的车、人、自行车)。但在真实的自动驾驶或机器人场景中,会遇到无数的长尾目标(如遗落的轮胎、奇形怪状的施工路障、甚至是一只突然窜出的动物)。
-
研究目的: 旨在开发一种 M3OD 框架,使其能够根据人类的自然语言提示(文本描述),在 3D 空间中检测并定位出训练集中**从未见过(Unseen/Novel)**的物体类别,实现真正的“零样本(Zero-shot)”3D 检测。
-
核心问题(痛点):
-
3D 数据的“语义贫乏”: 现有的 3D 标注数据集类别极其有限(通常只有不到 10 类)。
-
2D 与 3D 的知识鸿沟: 目前像 CLIP 这样的视觉-语言大模型(VLM)拥有极其丰富的“开放词汇”语义知识,但它们都是纯 2D 的,完全不懂 3D 深度和几何体积。如何将 2D 大模型的浩瀚语义知识,无损地“蒸馏”并对接到缺乏深度信息的单目 3D 空间中,是最大的技术壁垒。
-
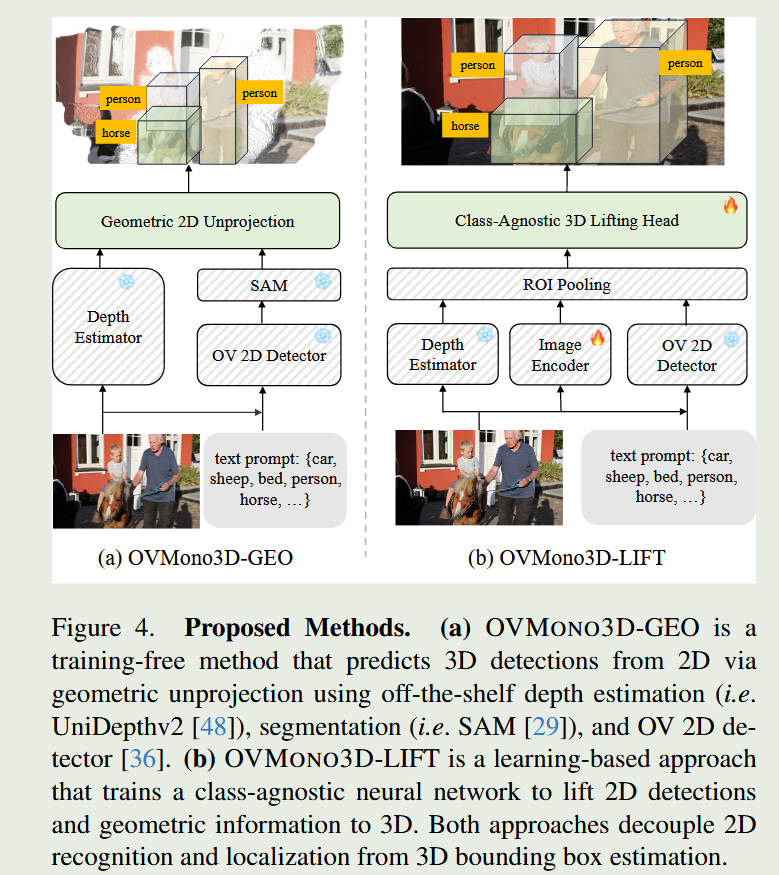
整体框架图
二、 研究方法、关键数据与结论
1. 核心方法:语义与几何的解耦与对齐
为了打破上述壁垒,开放词汇 M3OD 通常采用“分而治之”的框架:
-
2D 开放语义蒸馏 (2D Open-Semantic Distillation): 借用预训练的 2D 开放词汇检测器(如 Grounding DINO 或基于 CLIP 的模型)作为“教师”。在训练阶段,提取图像中所有潜在物体的 2D 文本-图像对齐特征,并强制 3D 检测网络(学生)去学习这些丰富的特征表示,从而让 3D 网络掌握识别万物的能力。
-
类别无关的 3D 几何估计 (Class-Agnostic 3D Geometry Estimation): 由于模型需要检测从未见过的物体,过去那种依赖特定类别先验知识(比如预设“汽车的平均长宽高”)的方法彻底失效。因此,模型被设计成将其“语义分类头”和“3D 几何回归头”完全解耦。几何分支被迫学习一套通用的物理法则(如何从透视形变中估算深度和通用体积),而不是死记硬背某种物体的尺寸。
2. 关键数据与主要发现
-
评测范式转移: 在 nuScenes 或 KITTI 数据集上,研究人员会将类别划分为“基类(Base classes,用于训练)”和“新类(Novel classes,训练时完全不可见)”。
-
突破性表现: 实验结果表明,该类框架在“新类”目标上的 3D 检测精度(如 3D AP)远超传统的闭集模型(传统模型在新类上得分通常为 0)。它证明了通过 2D 知识转移,单目 3D 网络完全可以具备零样本泛化能力。
3. 结论
单目 3D 目标检测不必被极少数标注类别所局限。通过巧妙利用 2D 视觉-语言大模型的语义先验,并结合类别无关的几何回归设计,系统能够实现对开放世界未知物体的有效 3D 感知。
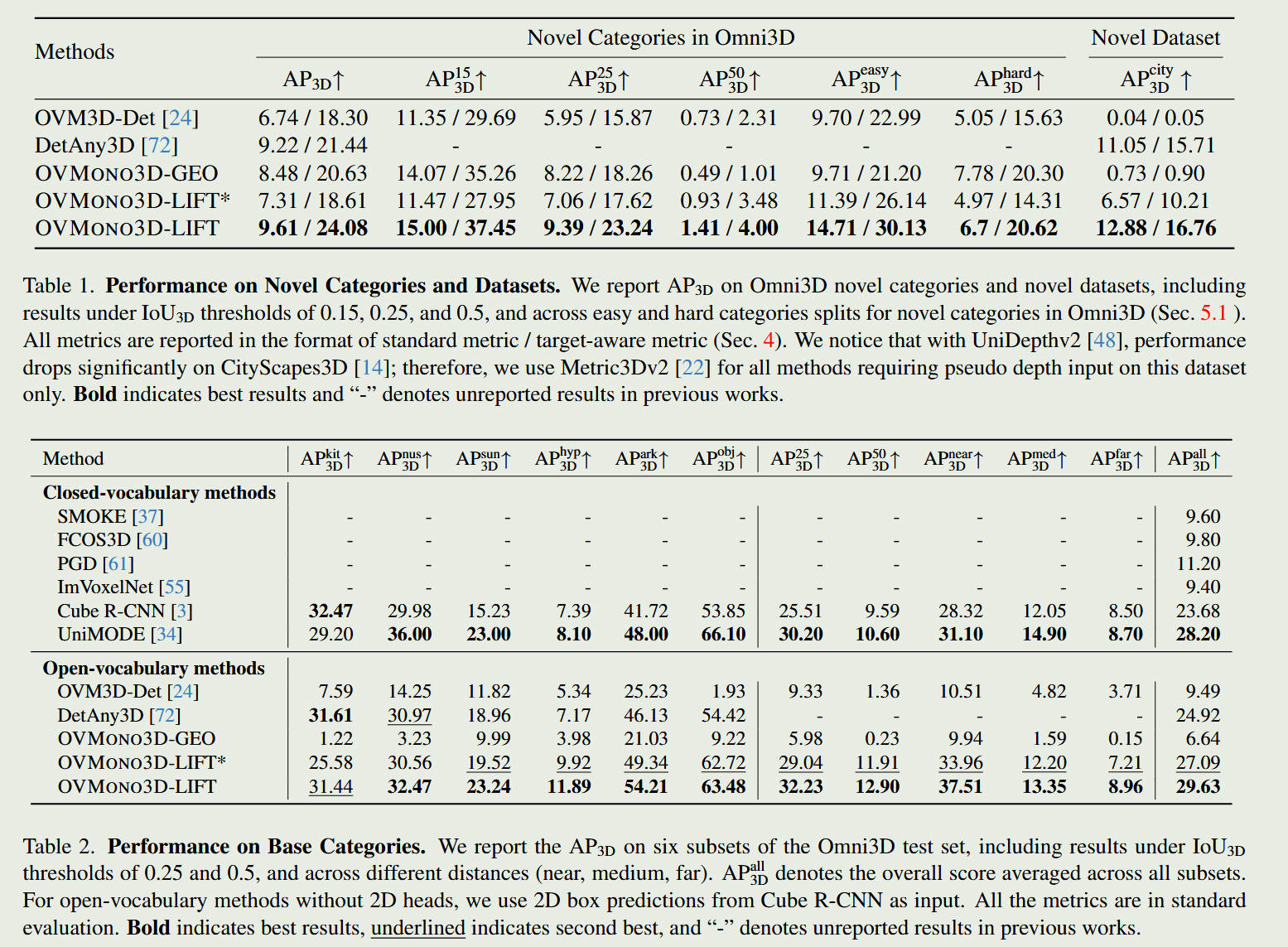
结果对比
三、 新颖概念通俗解释
-
开放词汇目标检测 (Open Vocabulary Object Detection):
传统的“闭集”检测就像是一个尽职但死板的保安,他脑子里只记了 3 张通缉令(车、人、猫),如果一只狗跑过去,他会视而不见。而“开放词汇”检测则像是一个连着大语言模型百科全书的超级保安。你只要用文字下达指令:“找出那个翻倒的红色锥形桶”,他就能理解这段话的含义,并在画面中精准锁定它,即使他以前从未被专门训练过识别锥形桶。
-
类别无关几何 (Class-Agnostic Geometry): 在不知道物体是什么的情况下,依然能估算它的大小和距离。就像你在黑夜里看到一个不知名的黑色轮廓,虽然你叫不出它的名字,但你的大脑依然能根据透视关系和参照物,大致判断出它离你有多远、大概有多大体积。这就是抽离了语义概念后的纯粹“物理几何感知”。
四、 优缺点客观评价与后续研究方向
优点:
-
极高的现实应用价值: 完美契合自动驾驶中最为棘手的“长尾场景(Long-tail Edge Cases)”,是迈向 L4/L5 级别高阶自动驾驶的必经之路。
-
打破数据标注瓶颈: 极大地降低了对昂贵 3D 边界框标注的依赖,可以充分利用互联网上几乎无限的图像-文本对进行预训练。
缺点与局限性:
-
3D 尺寸估算极其脆弱: 认识新物体容易(借用 CLIP),但准确估算它的 3D 尺寸极难。面对形状奇特的未知物体(如一辆加长铰接公交车),由于缺乏特定的 3D 尺寸先验,模型回归出的 3D 边界框往往与真实物理体积相差甚远。
-
对 2D 提示的强依赖: 如果物体在 2D 图像中被严重遮挡、截断或者因为光照极暗导致 2D 开放词汇模型未能提取出有效特征,3D 分支就会彻底变成“瞎子”。
极具潜力的后续研究方向(破局点):
这篇论文在处理未知物体时的脆弱性,恰好呼应了更深层次的底层视觉和宏观场景逻辑:
-
多粒度特征恢复 (Multi-Granularity Feature Restoration): 针对新类别物体因遮挡或极端光照导致的特征丢失问题,可以在特征蒸馏和几何估计之前,引入多粒度的特征修复机制。先在局部像素层面恢复其基础的几何纹理,再在全局语义层面补全其被遮挡的轮廓。只有将被破坏的视觉线索“修复”完整,开放词汇模型才能从容地对未知物体进行分类和 3D 回归。
-
引入场景拓扑正则化 (Scene Topological Regularization): 这是一个极其关键的约束手段。当模型面对未知物体(Novel Objects)时,往往会给出荒谬的 3D 坐标(比如预测一个未知的箱子悬浮在半空,或者和旁边的汽车相互穿模)。通过引入场景拓扑正则化,强制模型遵循物理世界的通用宏观法则——“所有物体必须依附于地面”、“物理空间不可重叠占据”。这样,即使系统不知道这个新物体到底是什么,也能用全局拓扑逻辑强行修正它不合理的 3D 位置,极大提升开放词汇 3D 检测的物理合理性。