OBMO: One Bounding Box Multiple Objects for Monocular 3D Object Detection

🏛️ 会议/期刊:IEEE TIP
📅 发表年份:2023
💻 开源代码:mrsempress/OBMO_patchnet
📄 论文题目:OBMO: One Bounding Box Multiple Objects for Monocular 3D Object Detection
🌟 一、 论文速览 (Executive Summary)
-
研究背景与痛点: 在自动驾驶领域,单目 3D 目标检测因硬件成本低、易部署而备受瞩目。然而,由于 2D 图像缺乏深度信息,系统面临着固有的“深度模糊性 (Depth Ambiguity)”痛点——即不同深度、不同物理尺寸的物体,在图像上可能呈现出完全相同的 2D 边界框。现有的单目检测器大多采用“一对一”的硬标签监督,强迫网络在模糊的特征下输出绝对唯一的深度值,导致训练极不稳定,收敛困难。
-
研究目的与核心贡献: 本文旨在从标签分配 (Label Assignment) 的独特视角化解深度模糊难题。其核心贡献在于提出了一个即插即用的 OBMO 模块:通过沿相机的视锥体平移真实目标的 3D 边界框,生成带有软标签分数的多个伪目标,将原本严苛的单点深度回归转化为平滑的深度分布学习,从而显著且一致地提升了主流单目 3D 检测器的性能。
💡 二、 核心概念“剥洋葱” (Concept Demystification)
-
核心概念 1:深度模糊性 (Depth Ambiguity)
- 通俗解释: 想象你闭上一只眼睛看世界(单目相机)。如果有人拿一个玩具小汽车放在你眼前,和把一辆真正的汽车停在百米开外,它们在你视网膜上占据的大小可能是一模一样的。此时,仅仅通过这个 2D 框的视觉外观,你很难判断它是“近处的小玩具”还是“远处的大车”。这就是深度模糊。
-
核心概念 2:视锥平移 (Viewing Frustum Shifting)
- 通俗解释: 我们可以把相机镜头到 2D 边界框的连线想象成一根无形的“糖葫芦竹签”(视锥射线)。OBMO 的做法不是让网络死死盯住竹签上的某一颗特定的糖葫芦(Ground Truth 深度),而是沿着这根竹签,前后移动目标的 3D 框,生成一连串大小成比例变化的“影子糖葫芦”(伪目标)。这样,网络看到的就是一条合理的可能性轨迹,而不是一个死板的点。
-
核心概念 3:软标签评分 (Soft Label Scoring)
- 通俗解释: 在考试中,如果一道估算题的标准答案是 50 米,学生回答 49 米,传统的“硬标签”会直接给 0 分(全错)。而 OBMO 的“软标签”机制就像是给分步骤:越接近 50 米得分越高,偏离越远分数越低。这种温和的评价方式鼓励网络先找到大概的范围,有效防止了训练初期的梯度崩溃。
🔍 三、 章节深度拆解 (Section-by-Section Deep Dive)
I. 引言 (INTRODUCTION)
-
关键点 (Key Points):
-
点明单目 3D 部署优势与深度模糊痛点。
-
批评现有的一对一 (one-to-one) 监督范式放大了深度估计的不确定性。
-
提出了一对多 (one-to-many) 的 OBMO 范式及两种配套的标签质量评分策略。
-
-
总结 (Summary): 本章巧妙地将单目 3D 检测中长期存在的“特征区分度不足”问题,转化为“标签设定过于绝对”的问题,为全文奠定了从标签端放宽约束的破局基调。
II. 相关工作 (RELATED WORK)
-
关键点 (Key Points):
-
梳理基于 LiDAR 和单目视觉的两大流派。
-
指出无论是基于直接回归(如 CenterNet 系列)还是深度感知(利用单目深度图辅助)的单目方法,最终都未能逃脱单一确定性标签的桎梏。
-
-
总结 (Summary): 本章通过对现有技术路线的梳理,精准锁定了传统单目检测网络在监督信号层面的共同盲区,反衬出 OBMO 机制的独创性和普适性。
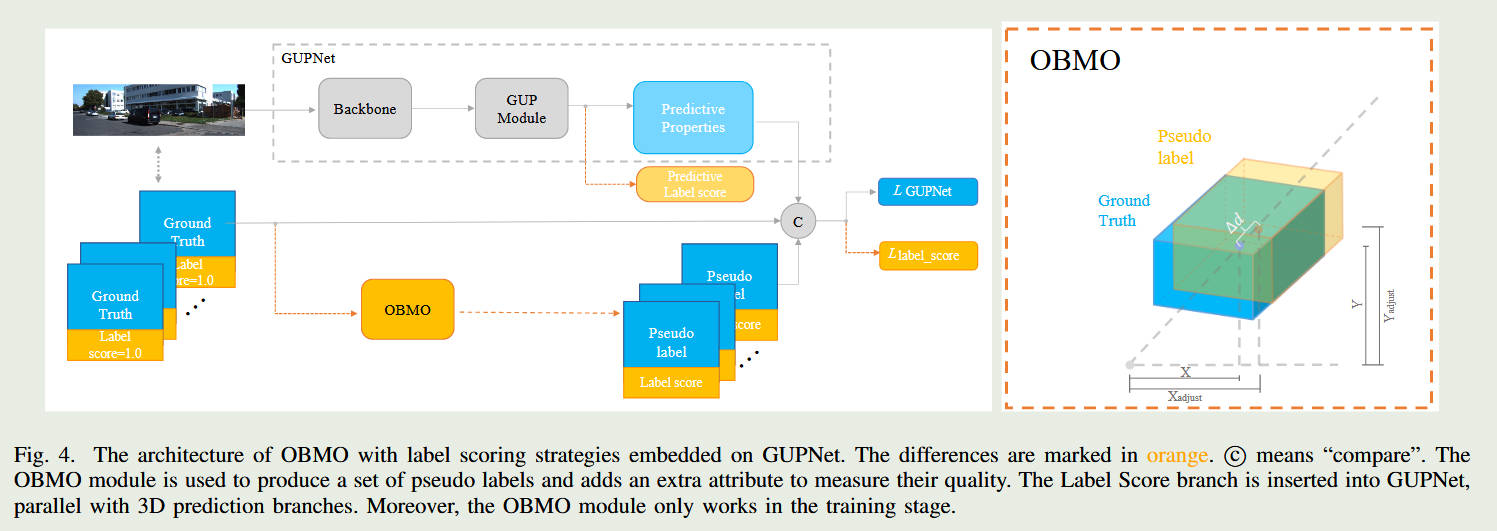
整体框架图
III. 方法 (APPROACH)
-
关键点 (Key Points):
-
数学重构: 基于针孔相机模型,严格推导了同一 2D 框下 3D 尺寸与深度之间的比例缩放关系。
-
标签生成端发力: 沿视锥射线以 $\pm 4%$ 或 $\pm 8%$ 等比例平移 3D 框,生成 $N$ 个伪目标,并通过 X-Z、Y-Z 比例保持物理常识。
-
损失函数端发力: 设计了基于 3D IoU 和基于线性距离的两种评分函数,通过辅助分支训练,赋予网络“评估深度可靠性”的能力。
-
-
总结 (Summary): 这是全文的硬核灵魂。OBMO 并没有修改网络提取特征的骨干(Backbone),而是做了一个优雅的“外部手术”:用一套符合 3D 透视几何法则的算法,硬生生造出了一套平滑的概率分布标签,让网络的学习过程从“走钢丝”变成了“走宽桥”。
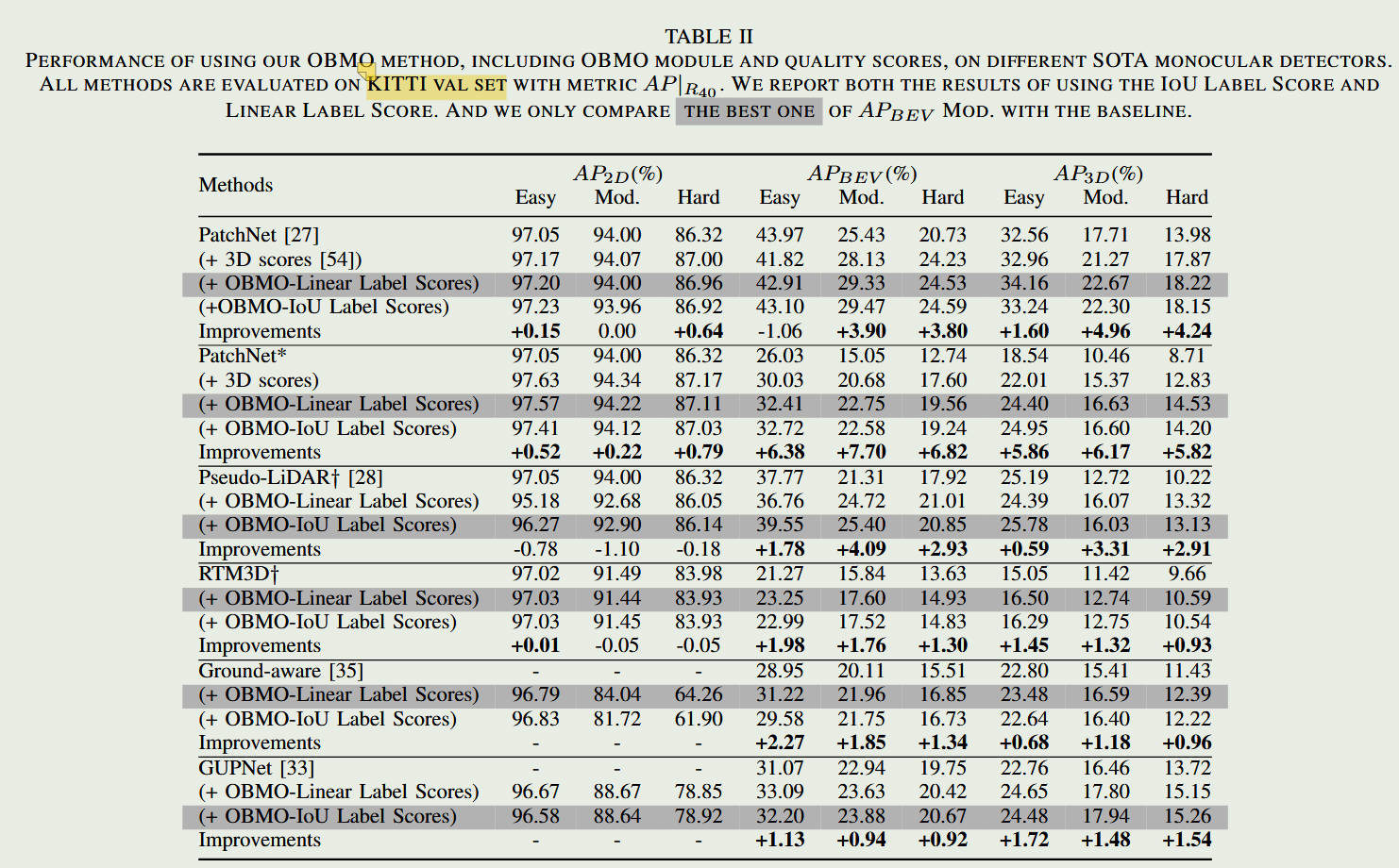
结果对比
IV. 实验 (EXPERIMENTS)
-
关键点 (Key Points):
- 普适性验证: 无缝接入 PatchNet、RTM3D、GUPNet 等多种截然不同的 Baseline,均实现涨点。
- 绝对性能: 在 KITTI 的 Moderate 难度下,BEV 和 3D mAP 获得了 $1.82% \sim 10.91%$ 的大幅提升。
- 消融数据: 证明了伪标签数量、平移幅度与几何约束必须精密配合,单独修改尺寸或过度平移会导致性能倒退
-
总结 (Summary): 实验部分通过极其详实的跨模型、跨数据集(KITTI & Waymo)验证,用压倒性的数据证实了核心假设:缓解标签端的“苛刻性”,确实能直接转化为检测精度的跃升和 Loss 曲线的平滑。
V. 结论与未来工作 (CONCLUSION & FUTURE WORK)
-
关键点 (Key Points):
-
OBMO 缩小了单目与 LiDAR 方法的差距。
-
承认在处理严重遮挡和截断(Occlusion and Truncation)时仍感吃力。
-
-
总结 (Summary): 客观陈述了突破与边界。标签优化无法无中生有地找回被物理遮挡的像素,这也是单目 3D 走向极致必须跨越的下一道坎。
⚖️ 四、 专家级锐评与启示 (Critical Evaluation & Future Work)
-
硬核优势 (Strengths):
-
大道至简,零推理负担: OBMO 纯粹在训练阶段(Training-time)的标签分配机制上做文章,推理阶段(Inference-time)无需任何额外操作或网络分支,这对于算力敏感的自动驾驶边缘端极其友好。
-
视角独特: 跳出了“加模块提特征”的无休止内卷,用几何先验化解了优化层面的病态问题。
-
-
潜在局限 (Weaknesses/Limitations):
- 治标不治本: OBMO 放宽了网络猜测深度的容错率,但如果图像特征本身已经被严重污染(如大面积遮挡),软标签也无力回天。它并没有赋予网络理解复杂空间重叠关系的能力。
-
后续研究方向 (Future Directions):
- “标签端”与“特征端/空间端”的强强联合: 既然 OBMO 能够在输出端优雅地处理深度不确定性,那么一个极具潜力的方向是将这种标签端的正则化,与网络内部的深度特征挖掘结合起来。例如,引入多粒度特征恢复 (Multi-Granularity Feature Restoration) 来增强网络对遮挡和模糊边缘的细粒度感知能力;同时,在宏观层面加入场景拓扑正则化 (Scene Topological Regularization),利用场景中其他物体的相对空间关系来进一步约束和校准深度预测。这种从特征表达、空间布局到标签优化的全链路协同,有望打造出极具鲁棒性的新一代单目 3D 检测范式。
🏷️ 五、 知识库标签 (Tags)
#OBMO #DepthAmbiguity #LabelAssignment #SoftLabels #ViewingFrustum #AutonomousDriving