OBMO: One Bounding Box Multiple Objects for Monocular 3D Object Detection

🏛️ 会议/期刊:IEEE TIP
📅 发表年份:2023
💻 开源代码:mrsempress/OBMO_patchnet
📄 论文题目:OBMO: One Bounding Box Multiple Objects for Monocular 3D Object Detection
这篇发表于 IEEE TIP (2023) 的经典论文 《OBMO: One Bounding Box Multiple Objects for Monocular 3D Object Detection》 切入点非常犀利。它没有在复杂的网络主干上做文章,而是直击单目 3D 目标检测在“底层数学物理逻辑”上的痛点,提出了一种极其优雅的“即插即用(Plug-and-play)”训练策略。
一、 背景、研究目的与核心问题
-
研究背景: 单目 3D 目标检测(M3OD)是一个典型的“病态(Ill-posed)”问题。因为单张 2D 图像在拍摄瞬间,不可避免地丢失了深度(Z 轴)信息。
-
研究目的: 旨在解决由于深度信息缺失导致的“网络训练极度不稳定”问题,通过提供一种更合理的标签分配策略,帮助模型更好地收敛并提升最终的 3D 检测精度。
-
核心问题(痛点):深度模糊导致的“一对多”窘境。 在真实的物理世界中,一个近处的小尺寸物体(比如一辆小轿车)和一个远处的大尺寸物体(比如一辆大卡车),当它们被透视投影到 2D 照片上时,可能拥有完全一模一样的 2D 边界框(Bounding Box)和极其相似的视觉特征。 然而,传统的训练方式是极其“死板”的。它拿着这个唯一的 2D 框,强迫神经网络必须输出一个唯一的、绝对准确的深度值(Hard Label)。这就导致网络在面对相似的视觉线索时,一会被惩罚“预测近了”,一会被惩罚“预测远了”,导致训练梯度来回震荡,陷入混乱。
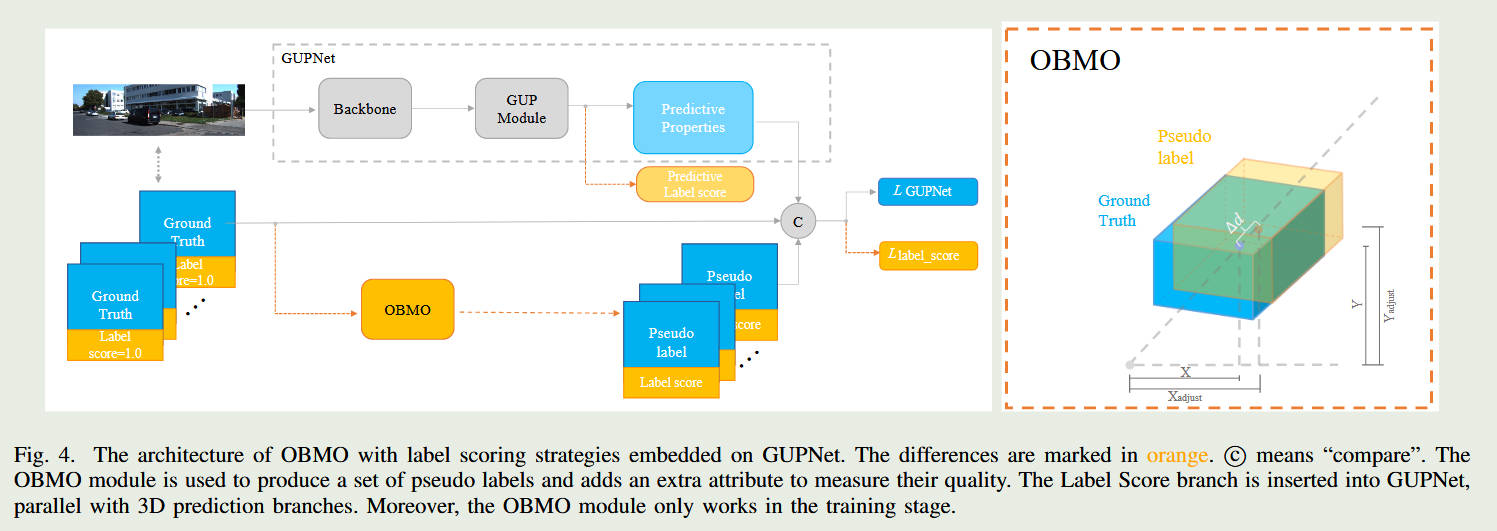
整体框架图
二、 研究方法、关键数据与结论
1. 核心方法:OBMO 框架
为了化解这种“死板”的训练带来的矛盾,作者提出了 OBMO(一个边界框,多个物体) 模块。它的核心思想是:既然存在深度模糊,那我们就不要强求网络给出一个绝对的死答案,而是让它学习一个“合理的深度区间”。
-
沿视锥平移生成伪标签 (Shifting along Viewing Frustum): 在训练时,对于图像中的每一个真实的 3D 标注框(Ground Truth),OBMO 会沿着相机的“视锥(Viewing Frustum)”射线方向,将这个 3D 框向前和向后平移,人为地复制出多个“伪 3D 框(Pseudo Labels)”。
-
双重标签打分策略 (Label Scoring Strategies): 这些平移出来的框显然不是完美的真实答案。为了告诉网络“它们有几分可信”,作者设计了两套打分机制。距离真实框越近、投影回 2D 图像后与原 2D 框重合度越高的伪标签,得分就越高;反之得分越低。
-
软分布学习 (Soft Distribution Learning): 通过这种方式,原本的一个“硬标签(必须等于某个深度)”,变成了一组带有概率分数的“软标签”。网络不再被逼着去猜那个唯一的精确值,而是学会了输出一个符合透视几何规律的深度概率分布。
2. 关键数据与主要发现
-
显著且广泛的提升: 作为一种即插即用的模块,作者将 OBMO 嵌入到了当时最先进的几种单目 3D 检测器中(如 GUPNet 等)。在权威的 KITTI 数据集上,不仅训练过程肉眼可见地变得更加平滑稳定,而且在中等难度(Moderate)下的 BEV(鸟瞰图)mAP 指标获得了 1.82% 到 10.91% 不等的巨大提升。在 Waymo 数据集上也同样验证了其有效性。
-
零推理成本: 由于这套“生成伪标签和计算概率分布”的机制完全是在**训练阶段(Training Phase)**计算损失函数时进行的,在模型真正部署推理(Inference)时会被全部丢弃,因此没有任何额外的计算延迟。
3. 结论
论文证明了:在单目 3D 检测中,承认并包容“深度模糊性”比盲目对抗它更有效。通过沿着视锥生成多个带有质量分数的伪目标(软标签),可以有效缓解一对多困境,引导网络学习到更鲁棒的 3D 几何特征。
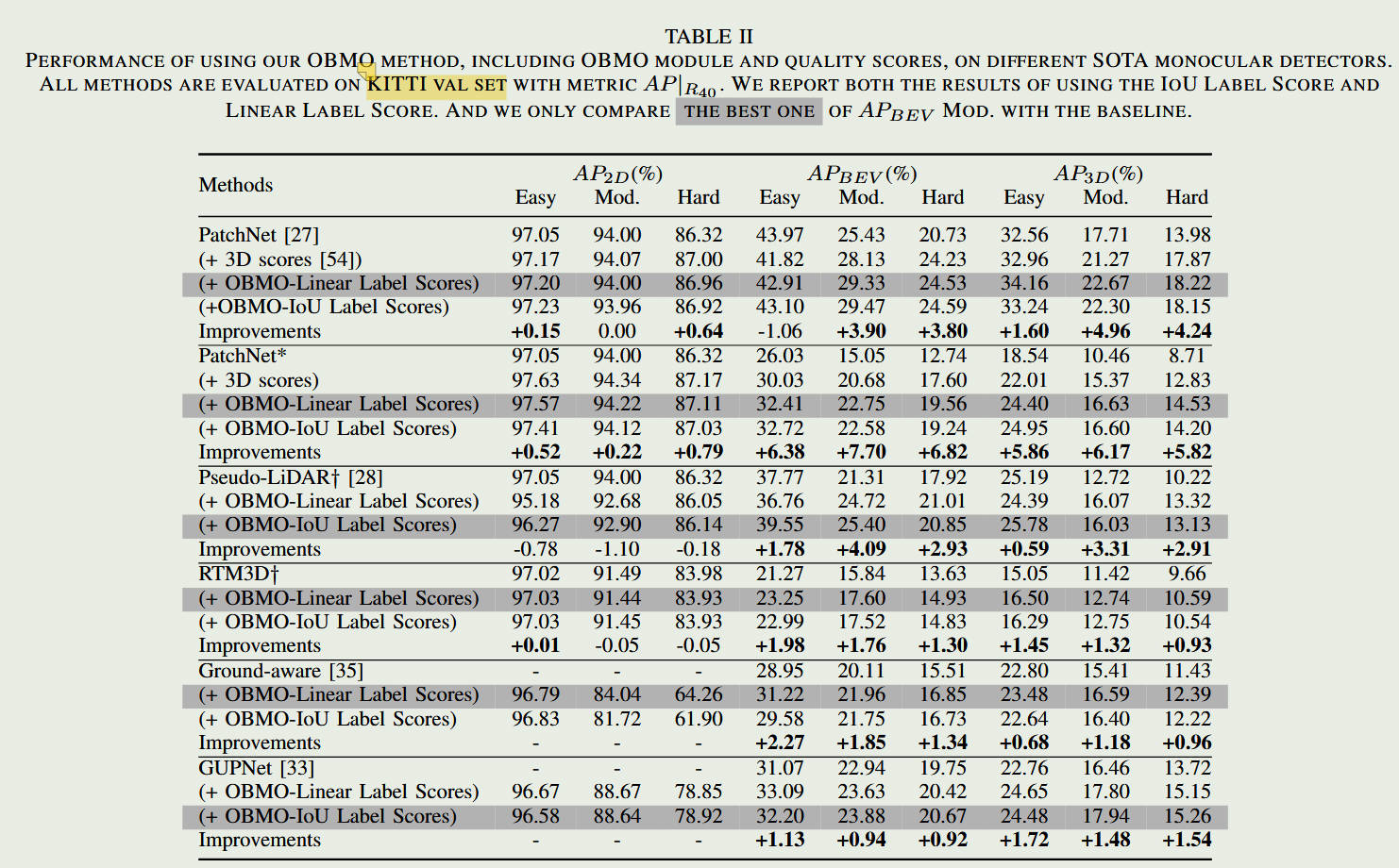
结果对比
三、 新颖概念通俗解释
-
视锥 (Viewing Frustum): 想象你拿着一个手电筒照向夜空,光束射出去形成的那个“越照越宽的圆锥体”就是视锥。相机的镜头就像这个手电筒,它拍下的 2D 画面,其实是 3D 世界在这个视锥里的投影。OBMO “沿着视锥平移”的意思,就是把一辆车想象成在这个光束轨道上前后滑动的模型。
-
硬标签 (Hard Label) vs. 软标签 (Soft Label): 硬标签就像是做“单选题”:这辆车的深度是 15.2 米,你预测 15.1 米就算错,网络会受到惩罚。 软标签(如 OBMO 提供的)就像是做“主观评分题”:真实深度是 15.2 米(100分),但你如果预测 14.5 米(给 80分可信度),预测 16 米(给 70分可信度)。这种宽容度极大地减轻了网络的学习压力,反而让它学得更好。
四、 优缺点客观评价与后续研究方向
优点:
-
物理逻辑严密: 非常精准地抓住了 2D 到 3D 投影的内在几何矛盾,用最符合物理直觉的方式(视锥平移)化解了它。
-
极简的工程美学: 不需要引入复杂的额外网络分支或外部数据,纯粹通过修改 Loss 计算时的 Label 形式就实现了性能飞跃,性价比极高。
缺点与局限性:
-
治标不治本: 虽然它极大地缓解了深度训练的震荡,但单目图像缺乏物理深度的本质依然存在。对于极端长尾场景(如极其罕见的特殊尺寸车辆),软标签依然无法无中生有地变出真实的绝对深度。
-
超参数敏感: 生成伪标签时,“平移的步长”、“平移的数量”以及“打分函数的衰减率”都属于人工设定的超参数,不同数据集可能需要反复调优。
可能的后续研究方向:
-
自适应视锥采样 (Adaptive Frustum Sampling): 目前 OBMO 的平移步长往往是固定的。未来的研究可以探索由网络自动根据图像特征(如物体的模糊程度、遮挡情况)来动态决定沿视锥平移的范围和密度。
-
时序视锥约束 (Temporal Frustum Constraint): 既然单图有深度模糊,如果引入视频序列(Video-based),将前一帧的预测结果通过运动学模型投射到当前帧的视锥中,用时序的物理一致性来过滤掉 OBMO 生成的那些不合理的伪标签,将能进一步收缩深度的概率分布范围。