Difficulty-Aware Label-Guided Denoising for Monocular 3D Object Detection

🏛️ 会议/期刊:AAAI
📅 发表年份:2026
💻 开源代码:MonoDLGD
📄 论文题目:Difficulty-Aware Label-Guided Denoising for Monocular 3D Object Detection
一、 背景、研究目的与核心问题
-
研究背景: 在基于 Transformer 的单目 3D 目标检测中,通过向真实标签注入噪声并让模型去重构(即查询去噪 Query Denoising),能有效加速模型收敛并提升几何感知能力。
-
研究目的: 旨在提出一种动态、自适应的去噪框架,通过显式的几何监督和对样本难度的精准把控,提升模型应对复杂驾驶场景的鲁棒性。
-
核心问题(痛点): 现有的去噪方法非常粗暴,它们对所有真实标签施加同等强度的随机扰动。然而,在实际道路上,不同物体的检测难度天差地别(近处完整的车很容易,远处被严重遮挡、截断的车极难)。如果对“Hard”样本也施加强烈的噪声扰动,模型原本就微弱的特征会被彻底摧毁,导致训练崩溃;反之,如果噪声太弱,对“Easy”样本又起不到施压和抗干扰训练的效果。
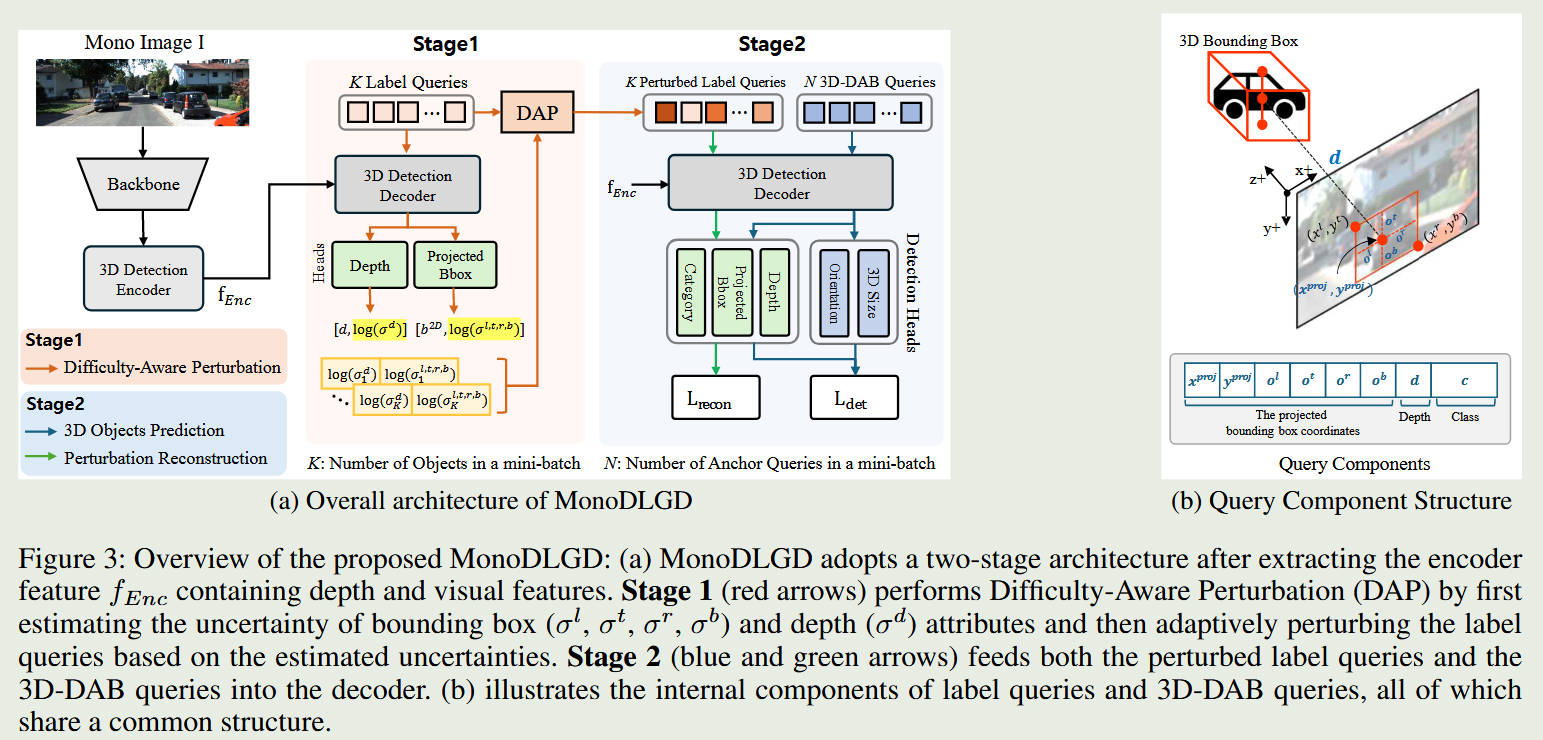
整体框架图
二、 研究方法、关键数据与结论
1. 核心方法:MonoDLGD 框架
为了解决“一刀切”的痛点,作者设计了两个关键组件:
-
标签引导的去噪与几何重构 (Label-Guided Denoising): 在训练时,系统会故意扰动带有丰富 3D 信息的真实标签(如投影的 2D 框、深度值),并强制模型通过一个共享解码器将它们还原。这为模型提供了极强的显式几何监督,逼迫它深刻理解 2D 像素与 3D 空间的关系。
-
难度感知扰动机制 (Difficulty-Aware Perturbation, DAP): 这是整篇论文的灵魂。DAP 能够基于实例级别的“预测不确定性”来动态调节加噪的强度。其核心策略是:遇强则强,遇弱则弱。对于容易检测的实例,施加大规模扰动以增强其泛化能力;对于遮挡或远距离等困难实例,则施加微小扰动,以保护其脆弱的特征线索不被破坏。
2. 关键数据与主要发现
-
在严苛的 KITTI 3D 目标检测基准测试中,MonoDLGD 表现惊艳。它不仅全面提升了检测精度,更重要的是,在衡量复杂场景的 Moderate 和 Hard 难度级别上,均达到了当前最先进(State-of-the-Art)的水平。
-
消融实验强有力地证明:如果没有 DAP 机制,单纯加噪会导致困难样本的性能退化;只有当“难度感知”与“标签重构”结合时,模型才能在所有难度级别上实现正向收益。
3. 结论
研究表明,在单目 3D 检测的去噪训练中,将“预测不确定性(难度)”与“噪声强度”挂钩是打破性能瓶颈的关键。这种难度感知的几何监督机制,有效促进了模型学习到更具判别性的几何特征。
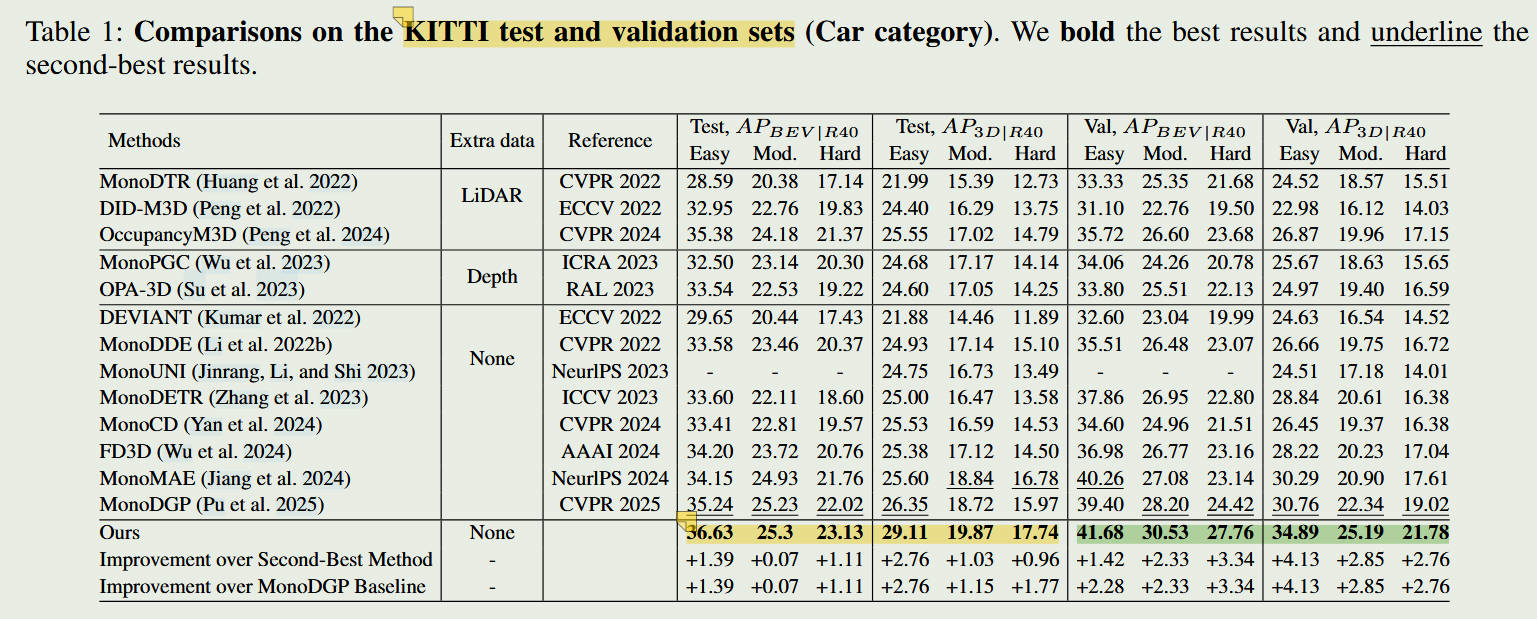
结果对比
三、 新颖概念通俗解释
-
标签引导的去噪 (Label-Guided Denoising): 传统的模型训练就像是开卷考试,直接看着图填 3D 框。标签引导去噪则是给模型安排了“魔鬼地狱周”:故意把正确答案(标签)揉皱、撕碎(加噪),然后让模型从一堆碎片中拼凑出完美的 3D 几何属性。这种极限施压极大提升了模型的“空间想象力”。
-
难度感知扰动 (Difficulty-Aware Perturbation): 就像健身房里的私教给人安排配重。面对初学者(对应极难的遮挡样本),如果教练直接上 100 公斤(强噪声),初学者当场就被压垮了;但面对举重冠军(对应近处清晰样本),只给 10 公斤(弱噪声)又起不到训练效果。难度感知就是这个“聪明的教练”,它能精准评估每个样本的承受能力,动态分配最合适的训练强度。
四、 优缺点客观评价与后续研究方向
优点:
-
精准的切入点: 敏锐抓住了由于距离、截断和遮挡导致的“实例级难度不平衡”现象,逻辑自洽,极其契合自动驾驶的真实长尾场景。
-
极高的性价比: 与前一篇的变分去噪类似,MonoDLGD 的所有“戏份”都在训练阶段完成。在推理部署时,这些去噪分支会被直接丢弃,不增加任何额外的网络参数和推理延迟。
缺点与局限性:
-
停留在数值维度的修补: MonoDLGD 仅对 1D/2D 的数值标签(如坐标、深度值)进行加噪和重构,但并没有在更深层次的视觉特征图(Feature Map)维度上去主动修复那些因物理遮挡而丢失的语义特征。
-
缺乏宏观的场景约束: 模型依然在“各自为战”,独立地对每个物体进行去噪重构,完全忽略了这些物体共处于同一个 3D 物理场景中。如果重构出来的汽车相互穿模,或者深度预测导致其悬浮在半空中,当前的孤立去噪机制是无法纠正的。
极具潜力的后续研究方向(破局点):
基于上述局限性,该领域接下来的突破口非常明确:
-
多粒度特征恢复 (Multi-Granularity Feature Restoration): 针对其局限于数值标签的短板,下一步亟需在特征提取阶段引入多粒度恢复机制。在进行坐标去噪之前,应当先在骨干网络(Backbone)或颈部(Neck)层级,将因遮挡导致的残缺特征进行从粗粒度(语义)到细粒度(几何)的逐层修复。只有底层特征足够丰满,上层的难度感知去噪才能发挥出最大威力。
-
场景拓扑正则化 (Scene Topological Regularization): 为了克服个体孤立重构导致的物理不合理现象,必须引入场景级的全局约束。在去噪重构的优化目标中,加入诸如物体与地面(Ground Plane)的依附关系、物体之间相对深度的拓扑排序等正则化项。这样,模型不仅能看清“个体”,更能理解整个 3D 场景的宏观拓扑结构,从而彻底打破单目 3D 检测的性能天花板。