MonoCT: Overcoming Monocular 3D Detection Domain Shift with Consistent Teacher Models

🏛️ 会议/期刊:ICRA
📅 发表年份:2025
💻 开源代码:GitHub 链接
📄 论文题目:MonoCT: Overcoming Monocular 3D Detection Domain Shift with Consistent Teacher Models
0. 一句话总结 (TL;DR)
(这篇论文用什么方法,解决了什么问题,达到了什么效果)
MonoCT 提出了一种基于一致性教师模型(Consistent Teacher)的半监督自适应框架,通过在目标域(Target Domain)引入伪标签一致性约束,有效解决了单目 3D 检测在不同数据集间迁移时的深度估计偏差问题。
1. 动机与问题 (Motivation)
(现有的单目3D检测有什么痛点?)
-
痛点:单目 3D 检测高度依赖相机的内参和场景布局。当模型从一个城市(源域)迁移到另一个城市(目标域)时,由于路面坡度、相机高度、物体尺寸分布的差异,会导致 3D 属性(尤其是深度)预估出现巨大偏差。
-
局限:现有的 UDA(非监督领域自适应)方法多关注 2D 特征对齐,但在 3D 空间中,微小的像素偏移就会导致巨大的 3D 框漂移。
MonoCT 整体框架图
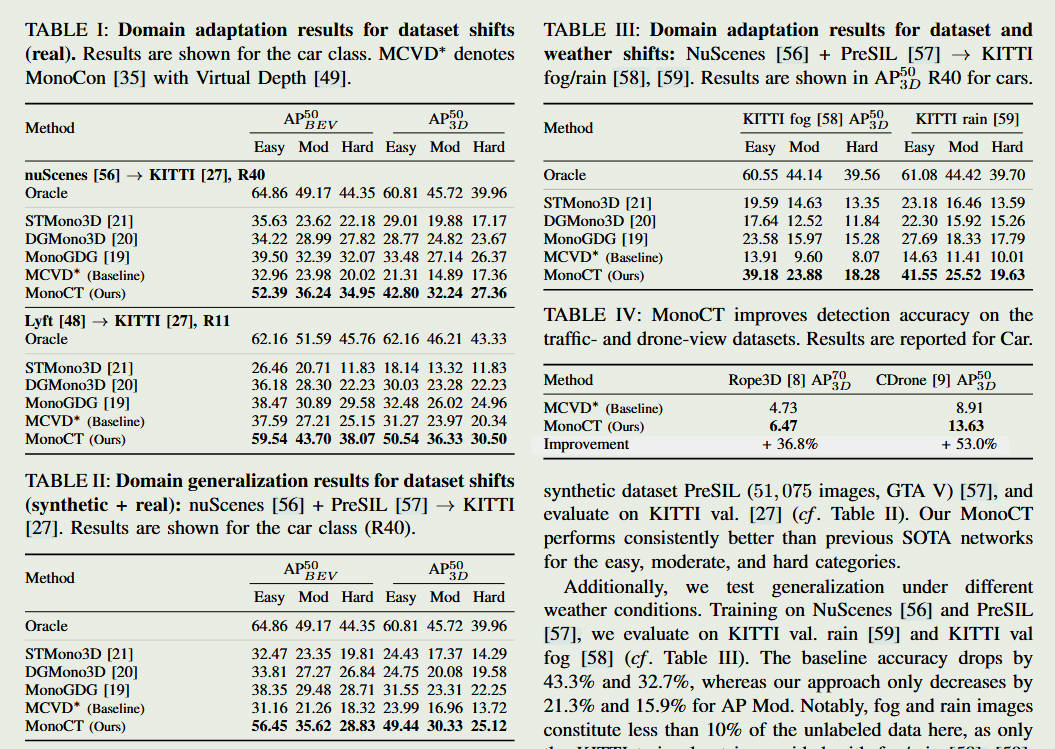
2. 核心方法 (Method)
(具体怎么做的?比如额外辅助模型是怎么引入的?数据增强的具体流程是什么?)
MonoCT 的核心在于“教师-学生(Teacher-Student)”架构的升级版:
-
Consistent Teacher (CT) 模块:
-
为了防止教师模型产生错误的伪标签(Pseudo-labels),MonoCT 引入了一致性正则化。
-
它要求模型在面对同一个物体的不同增强版本(如水平翻转、尺度缩放)时,输出的 3D 属性必须保持几何上的一致性。
-
-
3D 几何约束头 (Geometry-aware Head):
- 模型利用 2D/3D 几何投影关系(Height-to-Depth)作为辅助,通过已知的相机内参反向校验深度预测的合理性。
-
自监督深度增强:
- 在目标域(无标注数据)上,通过对比教师和学生模型预测的物体中心点偏移,来精细化调整物体在 BEV(鸟瞰图)下的位置。
3. 实验与启发 (Experiments & Takeaways)
(在 KITTI 上涨点了多少?对我自己的研究有什么可借鉴的?)
-
效果:在 KITTI → Waymo 的迁移实验中表现极其强悍。尤其是在跨相机参数的情况下,精度提升显著。
-
启发:
-
深度是关键:单目迁移的核心不是对齐特征图,而是校准深度。
-
伪标签质量:在你的研究中(如 MonoMGS),如果也面临数据不足,可以借鉴这种“一致性教师”的思想,利用未标注数据生成的伪标签进行半监督预训练。
-
BEV 投影:论文再次证明了在 BEV 空间进行约束比在图像平面约束更有效。
-