Mix-Teaching: A Simple, Unified and Effective Semi-Supervised Learning Framework for Monocular 3D Object Detection

- 🏛️ 会议期刊:TCSVT
- 📅 发表年份:2023
- 💻 开源代码:yanglei18/Mix-Teaching
- 📄 论文题目:Mix-Teaching: A Simple, Unified and Effective Semi-Supervised Learning Framework for Monocular 3D Object Detection
🌟 一、 论文速览 (Executive Summary)
-
研究背景与痛点: 单目 3D 目标检测(Mono3D)在自动驾驶等领域极具前景,但高度依赖昂贵的大规模 3D 标注数据。传统的半监督学习(SSL)若直接套用,会遭遇“水土不服”:因为 2D 到 3D 的推断本质上是病态(ill-posed)的,模型在无标注图像上生成的伪标签往往精度极低且召回率极低。低精度会带来严重的“确认偏差”(模型越学越偏),低召回率则会导致大量的目标漏检(模型把真实目标当成背景)。
-
研究目的与核心贡献: 本文旨在打破传统图像级伪标签的限制,提出一个简单、统一且即插即用的半监督单目 3D 检测框架。
-
提出 Mix-Teaching 框架:通过“分解-重组”操作,首次实现跨多帧图像的实例级高密度混合训练。
-
设计不确定性过滤器(Uncertainty-based Filter):精准甄别并剔除低质量伪标签,显著缓解确认偏差。
-
极强的普适性与惊艳的性能:作为通用插件,在 MonoFlex、GUPNet 等多种基线模型上均取得显著提升(在极低标注比例下提升高达 6% 以上,全量数据下成功登顶 KITTI 榜首)。
-
💡 二、 核心概念“剥洋葱” (Concept Demystification)
1. 分解与重组机制 (Decomposition and Recombination)
- 通俗解释: 想象你在整理一本学霸的课堂笔记(无标签数据)。传统方法是把整页笔记复印给后进生(学生模型)看,但笔记里其实夹杂了很多涂鸦和错误(低质量预测和漏检)。Mix-Teaching 的做法则是化身“精算师兼剪贴画大师”:把笔记里写得最漂亮、最正确的几个重点段落(高质量实例级 Patch)精细地“剪”下来(分解),然后“贴”到一张干净的白纸(无目标的背景图)或者其他标准教材(有标签图像)上(重组)。这样,学生模型每次读到的都是超高浓度、绝无干扰的“纯干货”。
2. 基于不确定性的过滤器 (Uncertainty-based Filter)
- 通俗解释: 考场上,有些差生虽然答案写得飞快(高置信度),但其实是在瞎蒙。怎么识别出这些“伪学霸”?过滤器的逻辑是让他做多遍同一道题(考察同一目标的不同预测集合)。如果他每次给出的答案(3D 框的定位位置)偏差极大,说明他内心极度“不确定”,这种答案必须扔掉;只有每次作答都高度一致且自信的,才会被收录进最终的“标准答案库”(高质量伪标签)。
🔍 三、 章节深度拆解 (Section-by-Section Deep Dive)
1. 引言 (Introduction)
-
关键点 (Key Points): 本节犀利地指出了 Mono3D 任务与传统 2D 检测在半监督场景下的本质区别——单目 3D 预测的定位误差极大。文章用详实的数据图表论证了盲目使用低质量伪标签会导致的灾难性后果(精度与召回率的双重崩塌),从而自然引出了放弃“整图混合”,转向“实例级混合”的核心动机。
-
总结 (Summary): 这一章是全篇的“破局点”,通过极其精准的痛点剖析,将“为什么单目 3D 搞不好半监督”这一宏大问题,具象化为了“伪标签质量与分布”的技术性障碍,为后续框架的设计提供了坚不可摧的逻辑支撑。
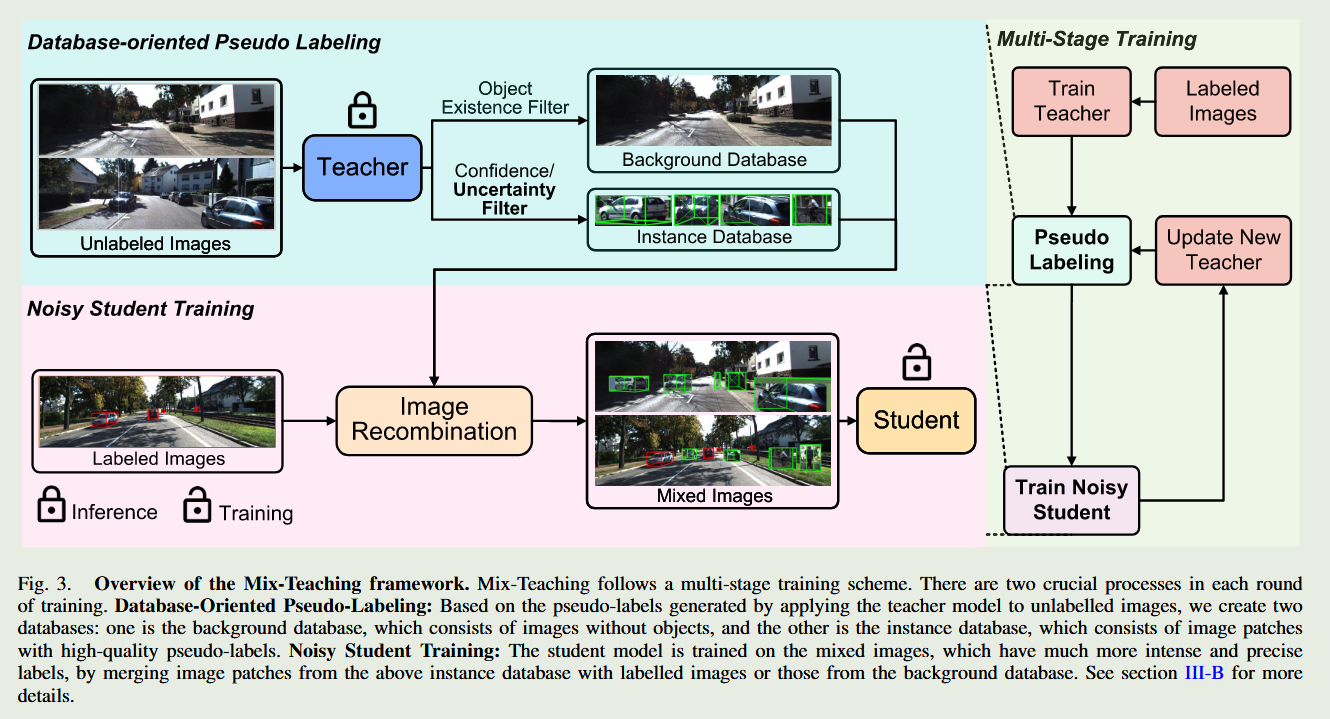
2. 方法 (Method)
-
关键点 (Key Points): 发力点主要集中特征表达端(数据级混合) 与 标签筛选端(双重过滤)。
-
自训练与伪标签生成: 教师模型对无标注数据进行预测。
-
双重过滤(Dual Filter): 结合传统的信心阈值(Confidence)和全新设计的 3D 空间定位不确定性公式(Uncertainty),剔除“高置信度但高误差”的毒药标签。
-
分解与重组: 将无标注图像拆解为“高质量前景 Patch 集合”与“纯背景集合”。随后,将前景 Patch 粘贴混合,形成具有高密度精准标签的全新训练样本,送入学生模型进行迭代优化。
-
-
总结 (Summary): 本章是全篇的技术灵魂。其最巧妙之处在于通过物理空间的“裁剪与粘贴”,极为优雅地绕开了单目 3D 中极难优化的深度误差问题。将一个复杂的 3D 几何难题,降维成了一个高效的数据重组流水线。
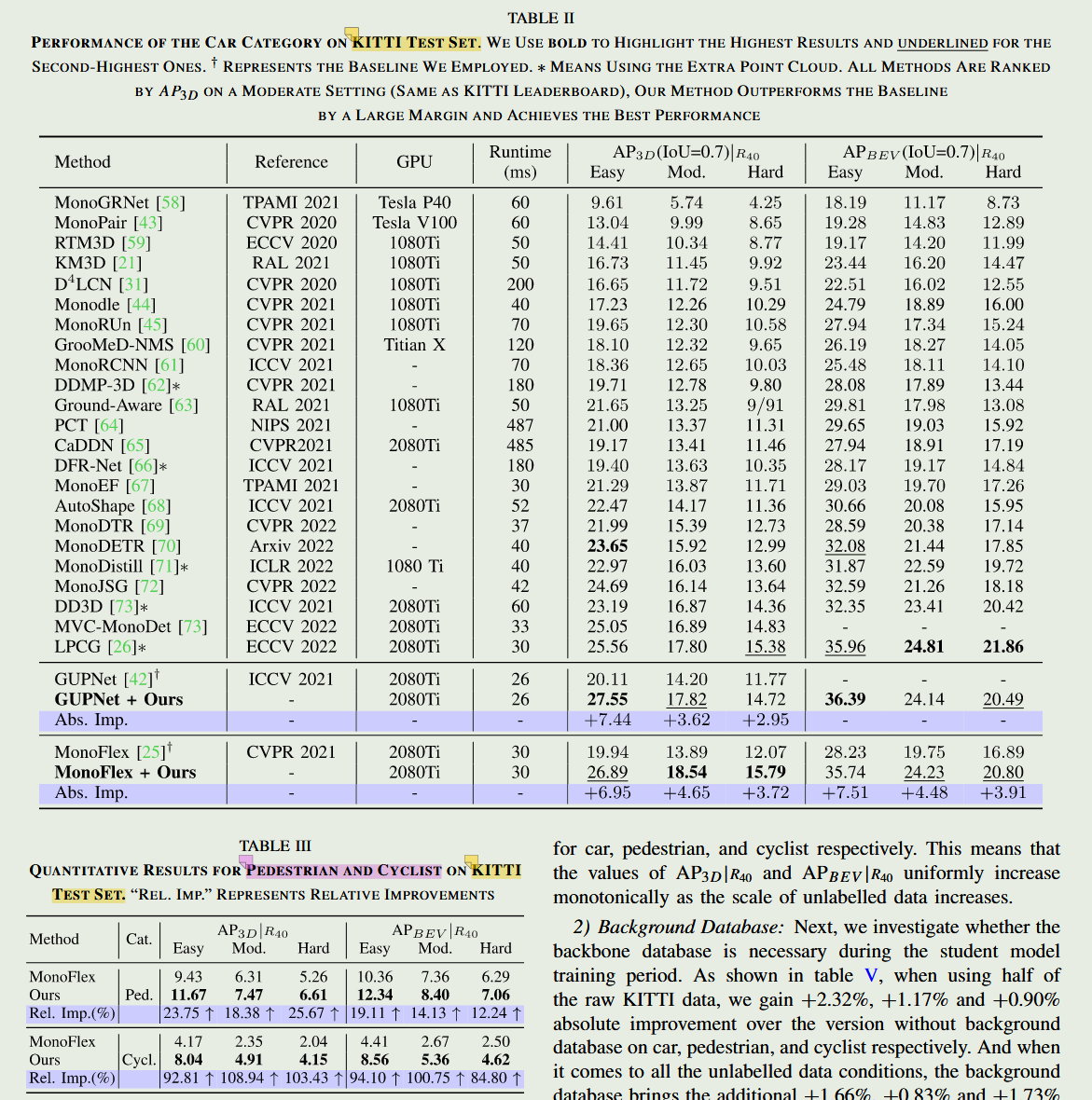
3. 实验 (Experiments)
-
关键点 (Key Points): 在自动驾驶权威数据集 KITTI 和 nuScenes 上进行了极其详尽的消融与对比实验。证明了在 10%、30% 等极低标注数据量下,Mix-Teaching 能带来雪中送炭般的性能暴涨(如 GUPNet AP 提升超 6%);即使在 100% 标注数据之上,引入额外 raw 图像也能实现锦上添花,强势登顶。
-
总结 (Summary): 实验部分堪称“暴力美学”,通过无懈可击的数据验证了该框架不仅是一个漂亮的理论模型,更是一个能在工业界实际落地的强力插件。
⚖️ 四、 专家级锐评与启示 (Critical Evaluation & Future Work)
-
硬核优势 (Strengths): 大道至简,降维解题。 该论文没有在晦涩的单目几何约束或复杂的网络架构上死磕,而是巧妙地在数据处理层面(Data-level)做文章。其提出的“跨帧实例级重组”打破了空间维度的桎梏,既解决了漏检带来的信息匮乏,又通过极高纯度的标签规避了确认偏差。此外,其作为 Unified Framework 的即插即用特性,赋予了它极高的工程复用价值。
-
潜在局限 (Weaknesses/Limitations): 破坏透视几何线索。 单目 3D 检测极其依赖图像中的透视规律(近大远小)和局部深度线索(如物体与地面的接触点)。当直接将一个车辆的 2D Patch “硬核”粘贴到新背景上时,可能会破坏原有场景的光度一致性,且新生成的图像可能违背真实的物理透视规律(例如把一辆在原图中距离相机 50 米的小车 Patch,贴到了新图的前景 10 米处),这可能会引入一定的空间伪影与认知偏差。
-
后续研究方向 (Future Directions):
-
深度与透视感知的智能混合 (Depth/Perspective-aware Mix): 在执行 Patch 重组时,引入场景的深度先验或地平面方程约束。不仅要“贴”,还要“贴得符合物理规律”,确保粘贴的车辆在图像坐标系中的大小和位置符合单目相机的物理成像逻辑。
-
融合时序动力学的半监督纯化: 从单张静态图像拓展至视频序列,利用前后帧中目标的运动学一致性(Kinematic Consistency)来进一步校验和过滤伪标签,实现从空间维度的“抠图”到时空维度的“轨迹平滑”。
-
🏷️ 五、 知识库标签 (Tags)
#单目3D目标检测 #半监督学习 #自动驾驶感知 #伪标签生成 #数据增强技术 #教师学生模型