LR3D: Improving Distant 3D Object Detection Using 2D Box Supervision

🏛️ 会议/期刊:CVPR
📅 发表年份:2024
💻 开源代码:无
📄 论文题目:Improving Distant 3D Object Detection Using 2D Box Supervision
这篇由 NVIDIA 等机构的研究人员发表在 CVPR 2024 的重磅论文 《Improving Distant 3D Object Detection Using 2D Box Supervision》(简称 LR3D),切入了一个目前高阶自动驾驶极其头疼的落地难题:远距离感知(Long-Range Detection)。它展示了如何用最廉价的标注,榨取单目视觉在远距离上的极限潜力。
一、 背景、研究目的与核心问题
-
研究背景: 在自动驾驶的 3D 数据集中(如 KITTI、nuScenes),3D 边界框的标注高度依赖激光雷达(LiDAR)的精确测距。然而,雷达点云在远距离(例如 40 米、100 米外)会变得极其稀疏,导致人工根本无法为这些远处的物体标注准确的 3D 框。
-
核心问题(痛点): 因为训练数据中缺乏远距离的 3D 标注,现有的单目 3D 目标检测模型在面对远距离目标时,性能会出现断崖式下跌。但是,远处的物体虽然没有 3D 雷达点,但在高分辨率的 2D 相机图像上依然清晰可见,人工画一个 2D 框非常容易。
-
研究目的: 旨在提出 LR3D 框架,让模型在仅有远距离 2D 框监督(没有远距离 3D 标注)的情况下,依然能精准估算出极远距离(超过 200 米)目标的 3D 属性。
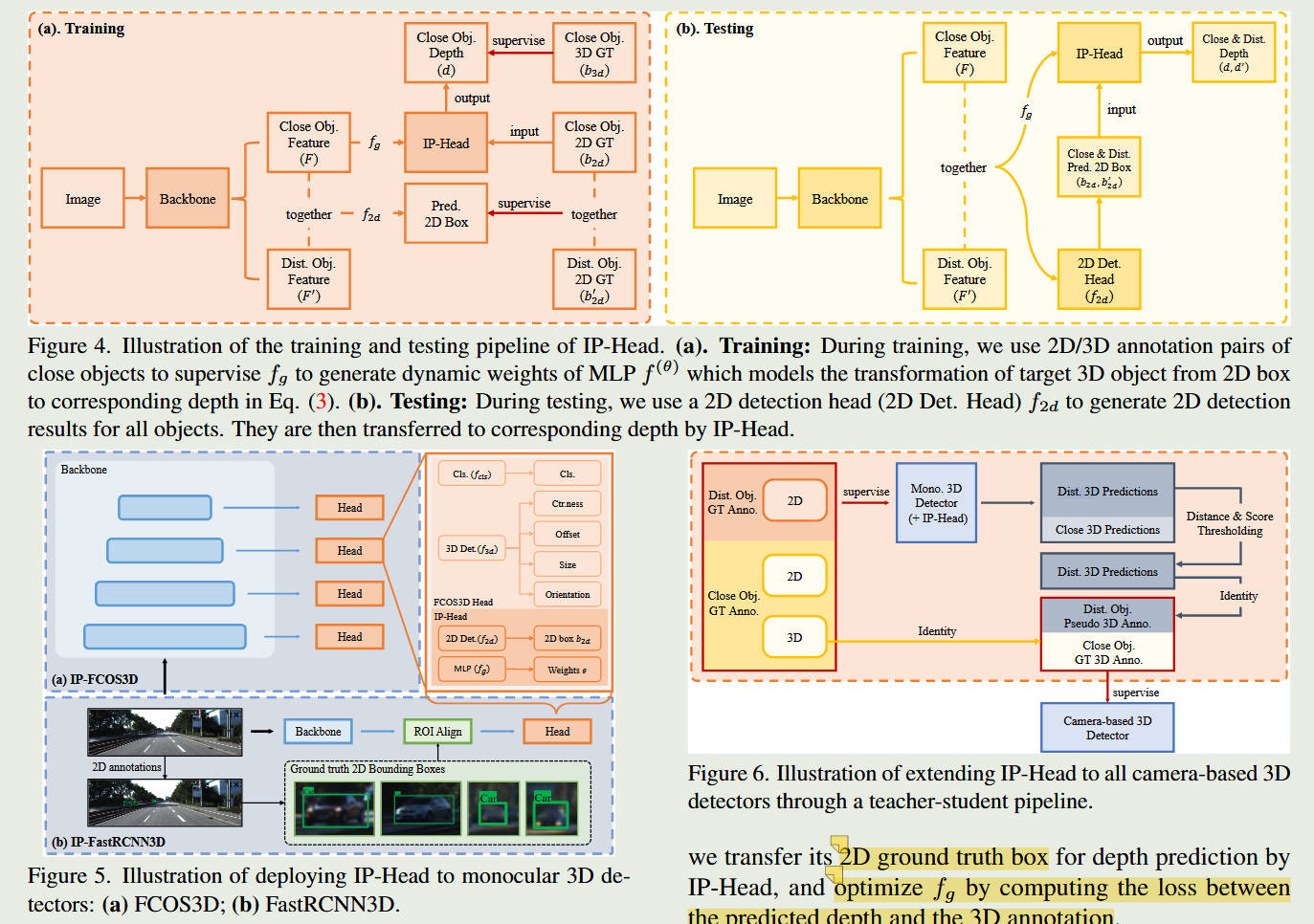
整体框架图
二、 研究方法、关键数据与结论
1. 核心方法:LR3D 框架 (近端学习,远端推断)
作者设计的这套框架极其巧妙,核心在于“经验的跨距离迁移”:
-
隐式投影头 (Implicit Projection Head, IP-Head): 在模型训练的近距离区域(例如 40 米以内),同时存在准确的 2D 框和 3D 标签。IP-Head 会在这里疯狂学习一种映射规律:特定的 2D 边界框尺寸,究竟对应着多远的 3D 深度。当它把这种“2D-3D 隐式映射”学透之后,面对 40 米外的目标,只需输入廉价的 2D 框,它就能直接推算出深度的概率分布。
-
投影增强策略 (Projection Augmentation): 为了防止模型在面对没见过的 2D 尺寸时崩溃,作者在训练时进行了数据增强。通过随机改变近距离目标的深度值,并利用相机内参反向计算出它对应的虚拟 2D 框,从而人为合成了海量的“2D框-深度”数据对,极大增强了 IP-Head 映射的鲁棒性。
2. 关键数据与主要发现
-
惊人的“无中生有”能力: 作者在实验中做了一个极端的测试:把数据集中 40 米以外的所有 3D 标注全部删掉,只保留 2D 标注。结果表明,搭载了 LR3D 的基线模型(如 FCOS3D),居然成功检测出了 200 米开外 的物体,且精度甚至媲美使用了全量 3D 标注(Full 3D Supervision)训练的模型。
-
通用插件: 该框架不仅适用于纯单目检测,还能无缝接入多视角(Multi-view)3D 检测网络中。
3. 结论
论文强有力地证明:对于单目 3D 检测而言,昂贵的远距离 3D 雷达标注并非不可或缺。只要充分利用近距离的 3D 监督建立隐式的透视映射,再辅以远距离廉价的 2D 框进行监督,就能以极低的成本解决长尾的远距离感知痛点。
三、 新颖概念通俗解释
-
隐式投影头 (IP-Head): 可以把它理解为老司机的“肌肉记忆”。一个经验丰富的司机在高速上开车,他不需要激光雷达,只要看一眼前车在挡风玻璃里占了多大面积(2D 框大小),就能立刻判断出前车离自己是 50 米还是 150 米(推算 3D 深度)。IP-Head 就是在用神经网络模拟人类这种“近大远小”的透视经验,建立从 2D 尺寸直达 3D 深度的捷径。
-
2D 框监督 (2D Box Supervision): 普通的 3D 模型遇到远处没标 3D 框的车,会直接当作背景忽略掉(导致漏检)。而 2D 框监督则是告诉模型:“虽然我不知道这辆车在 3D 空间里的确切深度,但我确定在这个 2D 像素框里有一辆车,你必须根据你的透视经验,给我把它在 3D 空间里的位置猜出来。”这种监督提供了一个极强的防漏检下限。
四、 优缺点客观评价与后续研究方向
优点:
-
直击落地痛点,极具商业价值: 彻底打破了高阶辅助驾驶中“远距离感知必须依赖昂贵高线束雷达标注”的迷信,极大地降低了数据闭环的成本。
-
优雅的数学与物理直觉: 将复杂的透视几何问题转化为数据驱动的隐式分布学习,且训练策略(投影增强)逻辑严密。
缺点与局限性:
-
极度脆弱的“错觉”: 由于深度完全依赖于 2D 框的尺寸,如果一辆近处的车被旁边的树木遮挡了一大半,导致目标检测器给出的 2D 框特别小,IP-Head 就会产生严重的错觉,误以为这是一辆在 200 米外的车。
-
缺乏全局场景意识: IP-Head 的映射仅仅发生在单个物体的独立计算分支中,完全没有考虑到路面起伏或其他车辆的空间参照关系。
极具潜力的后续研究方向(破局点):
基于上述遮挡引发的“深度错觉”问题,后续在架构设计上有两个极其明确的突围方向:
-
结合多粒度特征恢复 (Multi-Granularity Feature Restoration): 针对因截断或遮挡导致的 2D 边界框尺寸畸变,亟需在将特征送入 IP-Head 之前引入多粒度修复机制。通过提取周围的语义线索,先在特征维度上将被遮挡的车辆轮廓“脑补”完整,再基于修复后的完整多粒度特征去推算深度,就能彻底打破远距离遮挡带来的深度预测崩溃。
-
引入场景拓扑正则化 (Scene Topological Regularization): 孤立的隐式投影是盲目的。在长距离预测中,必须将单个物体的深度预测纳入全局场景的拓扑网络中。通过加入“远距离车辆必须依附于延伸的道路地平面”以及“视觉上重叠的 2D 框必须满足 3D 遮挡的深度排序”等场景拓扑正则化约束,可以强行利用宏观物理法则纠正 IP-Head 产生的离谱偏移。
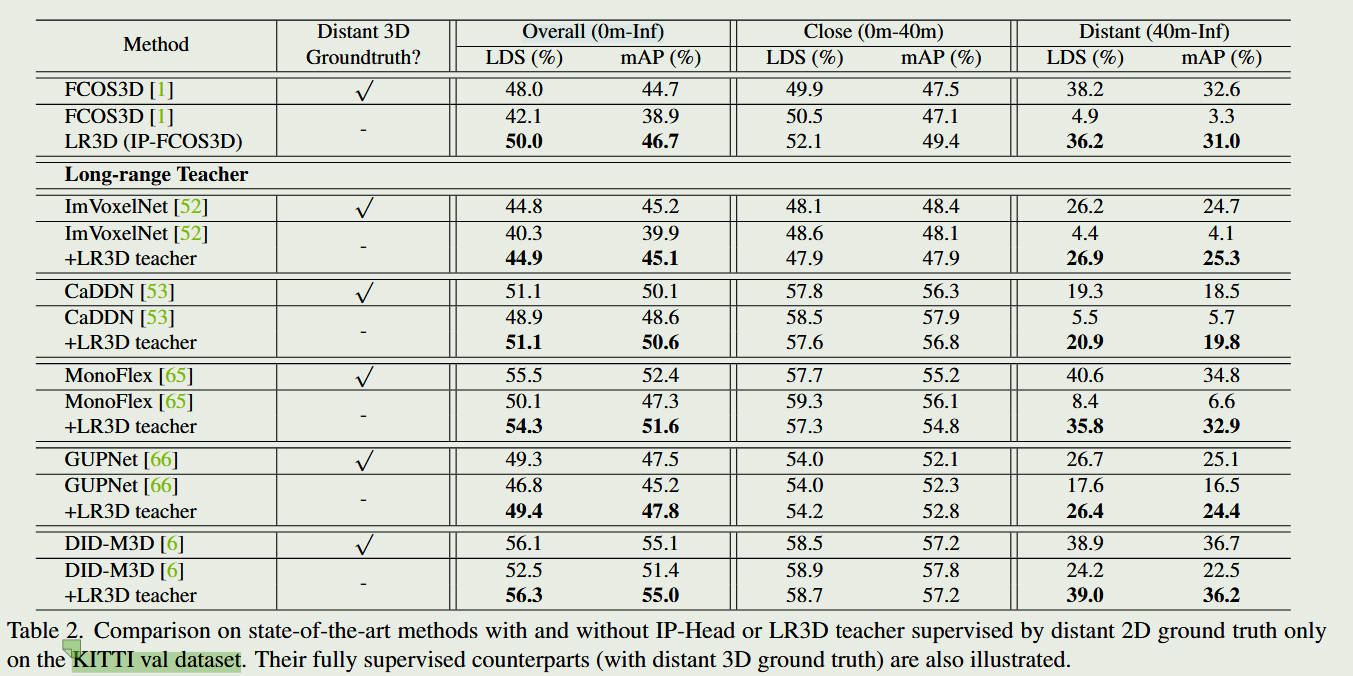
结果对比
到此结束