Iter3DDet: Depth Guided Iterative Fusion and Refinement for Monocular 3D Object Detection

- 🏛️ 会议期刊:TCSVT
- 📅 发表年份:2025
- 💻 开源代码:无
- 📄 论文题目:Iter3DDet: Depth-Guided Iterative Fusion and Refinement for Monocular 3D Object Detection
📄 基本信息
| 属性 | 详情内容 |
|---|---|
| 年份 | 2025年 |
| 期刊/会议 | IEEE Transactions on Circuits and Systems for Video Technology (TCSVT) |
| 作者团队 | Cheng Feng, Congxuan Zhang, Zhen Chen, Weiming Hu, K. Lu, Liyue Ge (北航/中科院自动化所等) |
| 开源情况 | 核心代码及相关衍生项目已在 GitHub 平台开源共享 (https://github.com/PCwenyue/ACR-Net-TCSVT 等) |
| 论文地址 | Iter3DDet: Depth-Guided Iterative Fusion and Refinement for Monocular 3D Object Detection |
| Summary | 本文针对单目3D检测中深度估计不准与前景目标深度分布存在长尾噪声的核心痛点,提出 Iter3DDet 框架。通过联合图像分割与几何约束预测目标深度,引入高斯归一化尺度先验抑制长尾噪声,并生成高质量伪点云;随后利用首创的点-体素双分支 Transformer (PV-DT3D) 进行提案感知与特征的迭代精细化,在 KITTI 基准上实现了验证集与测试集精度的显著跃升。 |
🌟 一、 论文速览 (Executive Summary)

研究背景与痛点
在当今自动驾驶与具身智能环境感知领域,三维目标检测(3D Object Detection)构成了车辆进行路径规划与避障决策的安全基石。从传感器模态的演进历程来看,激光雷达(LiDAR)凭借其能够提供高保真、结构化且无视光照的三维点云数据,长期霸占着三维感知性能排行榜的顶端 。然而,激光雷达方案存在着不可回避的商业化阿喀琉斯之踵:极其高昂的硬件采购成本、极为苛刻的机械标定要求以及在雨雪雾霾等恶劣天气下严重的信号衰减。这些物理与经济层面的桎梏,迫使学术界与工业界将目光转向了更具普适性和低成本优势的纯视觉方案 。
单目三维目标检测(Monocular 3D Object Detection)正是这一背景下诞生的“圣杯”级任务。其核心愿景是仅利用单个前向摄像头捕捉的高分辨率 RGB 图像,同时实现目标的二维语义识别与三维空间定位 。然而,这一任务在数学与几何本质上属于一个高度不适定的逆投影问题(Ill-posed Inverse Projection Problem)。在单目相机的透视投影成像过程中,三维世界中沿着相机光心射线方向的深度维度(Z轴)被彻底压缩并丢失。这种深度的缺失引发了灾难性的连锁反应:不仅导致目标的三维绝对尺度与空间距离充满模糊性,更使得网络在面对复杂交通场景中频繁出现的严重遮挡(Occlusion)与目标截断(Truncation)时,变得异常脆弱 。
现有的单目检测算法在尝试跨越这一鸿沟时,普遍陷入了不同的技术瓶颈。早期的纯二维特征延伸方法仅仅依赖局部视觉纹理进行黑盒回归,完全丧失了对场景级三维空间结构与长距离物体间深度拓扑关系的理解 。随后兴起的伪激光雷达(Pseudo-LiDAR)范式,虽然通过前置的单目深度估计网络将图像像素强行升维重构为 3D 点云,试图复用成熟的 LiDAR 检测框架,但其鲁棒性依然难以令人满意 。深度剖析其失效根源可以发现,由于缺乏多视角的几何约束,单目深度估计在前景目标边缘极其容易产生严重的“彗星拖尾”效应,并在整体深度分布上呈现出高度不确定的长尾分布噪声(Long-tail Noise)。这种底层数据的结构性崩塌,使得后续的任何检测算法都如同建立在流沙之上,最终导致目标定位出现惊人的误差 。亟需一种能够主动感知并修正深度误差、在特征层面深度融合几何与语义的新型框架来打破这一僵局。
研究目的与核心贡献
本文的研究目的在于彻底颠覆传统的“深度盲猜-单次回归”模式,通过构建深度与语义特征的高度耦合机制以及自适应的迭代优化网络,从根本上解决伪点云数据中由于深度不确定性带来的长尾噪声与定位漂移问题。
本论文的突破性核心贡献可高度凝练为以下三点: 首先,提出了一种基于联合图像分割与几何约束的创新目标深度预测范式。该机制不仅能够精准预测场景级深度,更能输出深度预测的置信度度量,通过将场景全局深度与目标局部深度深度融合,实现了最佳的目标初始空间定位 。 其次,创造性地引入了利用高斯函数归一化的目标尺度(Target Scale)作为强大的先验信息。这一机制犹如在网络中植入了一个“物理常识过滤器”,强力切断了深度分布不确定性带来的长尾噪声,从而生成了质量前所未有的高保真伪激光雷达点云 。 最后,设计并集成了一种极具前瞻性的点-体素双分支 Transformer(PV-DT3D)架构。在生成区域提案(Region Proposals)后,通过该双分支编码器-解码器网络,在空间维度与通道维度上进行特征的迭代融合与边界框的精细化微调,最终在 KITTI 数据集上刷新了多个难度级别的性能上限 。
💡 二、 核心概念“剥洋葱” (Concept Demystification)
为了深刻理解 Iter3DDet 的技术内核,必须对其支撑框架的几个高维学术概念进行解构。本节将采用降维打击的方式,层层剥开这些概念晦涩的数学与几何外衣。
联合分割与先验引导的深度约束 (Joint Segmentation and Prior-guided Depth Constraint)
在传统的伪点云生成管线中,网络通常对整张图片进行无差别、一视同仁的深度回归。这种方式在平坦的路面上表现尚可,但一旦遇到车辆边缘或复杂的背景交界处,深度值就会发生剧烈的跳变与渗透。本文提出的联合分割与几何约束机制,本质上是赋予了深度估计网络“轮廓意识”。
可以通过一个生活化的比喻来理解:假设你在一张平面的白纸上画了一辆汽车,现在你要把它剪下来并折叠成一个立体的纸模。传统方法是闭着眼睛乱捏,很容易把背景的树木也连带着捏进汽车的车身里(这就形成了所谓的拖尾点云)。而联合分割机制,就像是给了你一把极其锋利的“语义剪刀”,先严丝合缝地沿着汽车的轮廓把它从背景中彻底剥离出来,然后再利用几何透视规则(近大远小)去单独推算这辆车的深度。这种通过置信度度量将目标深度与场景大背景深度进行动态融合的做法,确保了目标不会被融化在错乱的背景空间中 。
高斯归一化尺度先验与长尾噪声抑制 (Gaussian-Normalized Scale Prior and Long-tail Noise Suppression)
“长尾噪声”是伪激光雷达领域最臭名昭著的毒瘤。在统计学上,它意味着极端的、离谱的预测误差不仅时有发生,而且占据了相当大的比例。由于单目视觉缺乏三角测距的硬性物理约束,网络在猜测某些无纹理或被遮挡的汽车距离时,偶尔会给出一个极其夸张的深度值。
本文采用的高斯函数归一化的尺度先验,其核心哲学在于“用物理常识去对抗深度幻觉”。在现实世界中,尽管汽车的型号各异,但其真实的三维物理尺寸(长宽高)必然符合一个特定均值和方差的高斯概率分布(Gaussian Distribution)。网络在运行时会进行一次逻辑自省:根据当前图像上汽车的二维像素大小,结合预测的超远深度,反算出的汽车物理体积是否像一头大象甚至一栋楼那么大?一旦反算结果落在高斯分布的极小概率尾部区域(即长尾),系统就会判定此时的深度预测极度不可靠,并强行利用高斯先验中心点的统计特征,将这个离谱的深度值“拽”回到合理的分布区间内。这种操作极大地净化了输入到后续检测器中的点云质量 。
点-体素双分支 Transformer (Point-Voxel Dual Transformer, PV-DT3D)
在将优化后的高质量伪点云送入检测阶段时,如何高效榨取其中的特征信息是另一个巨大挑战。纯基于点的网络(如 PointNet 系列)能够精准保留几何细节,但在处理大规模场景时计算复杂度呈爆炸式增长且缺乏局部邻域上下文;而纯基于体素的网络(如 VoxelNet)虽然计算高效,但其网格化的离散操作不可避免地抹杀了细粒度的几何边界 。
Iter3DDet 中提出的 PV-DT3D 架构,巧妙地实现了“鱼与熊掌兼得”。这个架构可以被形象地比作一个经验丰富的侦探同时使用了“显微镜”和“广角监控”。体素分支(Voxel Branch)如同广角监控,通过提案感知的体素集合抽象模块(Proposal-aware voxel set abstraction),快速扫描整个场景,确立宏观的空间结构与目标大体位置(生成初步提案);而点分支(Point Branch)则如同显微镜,精确聚焦在目标表面的关键点上。随后,双 Transformer 编码器-解码器像一个中央处理器,在点层级(Point-wise)进行精细的几何特征自注意力交互,同时在通道层级(Channel-wise)捕捉高维语义特征的依赖关系。两者相辅相成,通过多轮迭代使得最终的 3D 边界框完美贴合目标 。
🔍 三、 章节深度拆解 (Section-by-Section Deep Dive)
本节将严格遵循学术报告的逻辑脉络,对论文的各个核心章节进行深度两段式拆解,剖析其技术发力点与整体逻辑链条中的承启作用。
1. 深度迷局:引言与单目感知的底层困境 (Introduction)
-
关键点 (Key Points):
-
发力点:痛点挖掘与宏观破局。 引言部分高屋建瓴地论述了深度学习在各类视觉任务中的长足进步,并尖锐地指出了单目3D目标检测长期停滞不前的物理学根源——二维平面图像无法提供真实的物理度量(Metric Information)空间约束 。
-
文章引用了大量早期研究指出,仅仅依赖边界框、分割掩码或目标坐标等局部视觉特征,不仅容易受到截断和遮挡等环境因素的严重干扰,更会在复杂多目标场景下迷失物体间的相对深度拓扑关系 。
-
针对近年来颇受追捧的“伪激光雷达(Pseudo-LiDAR)”数据驱动路线,作者直击要害地提出:相较于真实的 LiDAR 脉冲回波,伪点云在目标位置精度和前景深度分布确定性上存在不可逆的劣势。正是这两个致命问题,构成了现有算法性能无法突破的玻璃天花板 。由此,文章顺理成章地引出了联合深度精炼与 PV-DT3D 迭代机制这一革命性解法。
-
-
总结 (Summary):
作为全篇逻辑链条的“起”点,引言并未纠缠于细枝末节的算法调参,而是直刺单目检测的物理与几何软肋。它通过建立一个严密的逻辑推导序列(单目缺陷 $\rightarrow$ 深度不准 $\rightarrow$ 伪点云长尾噪声 $\rightarrow$ 必须引入几何先验与迭代微调),为读者铺设了一条无可辩驳的研究动机之路,成功奠定了整篇论文极其硬核且务实的基调。
2. 范式更迭:相关工作与技术演进路线 (Related Work)
-
关键点 (Key Points):
-
发力点:前沿扫掠与技术定位。 本节系统性地梳理了 3D 目标检测从强依赖激光雷达到纯视觉轻量化探索的百年孤独。
-
为了清晰展示各类范式的优劣势与演进脉络,本报告特将论文中涉及的核心文献流派进行结构化总结,如下表所示:
-
| 技术流派与代表作 | 核心方法论 | 性能瓶颈与局限性 |
|---|---|---|
| 纯 2D 延伸法 (如早期基于先验的几何约束法) | 依赖地面平坦假设、2D-3D 边界框一致性以及严格的目标长宽高先验 | 泛化能力极差,路面稍有起伏或遇到非标准目标即刻崩溃。 |
| 基础伪激光雷达法 (Baseline Pseudo-LiDAR) | 单目深度估计 $\rightarrow$ 生成深度图 $\rightarrow$ 反投影为 3D 点云 $\rightarrow$ 送入传统 3D 检测网络 | 前景与背景边界严重粘连(彗星拖尾),长尾深度噪声引发定位漂移 。 |
| Transformer 深度感知法 (如 MonoDETR, MonoDTF) | 抛弃点云转换,直接在网络内部构建深度编码器与视觉编码器,通过注意力机制进行特征层级的深度线索注入 | 对大尺度场景的几何抽象能力不足,依然受困于单次回归的高方差。 |
-
文章指出,虽然诸如 MonoDETR 和后续的改进工作通过 Transformer 引入了深度指导的交互机制,但它们在面对极端深度噪声时依然缺乏主动的几何修正能力 。此外,像 Sparse4D 这类尝试通过稀疏采样进行 4D 关键点迭代微调的网络,证明了“迭代(Iterative)”思想在处理复杂空间-时序特征时的巨大威力 。这就为本文采用高斯先验修正深度并引入双 Transformer 进行迭代微调提供了坚实的文献支撑。
-
总结 (Summary):
相关工作章节扮演了完美的“承”接角色。通过对旧有“规则驱动”、中期“数据转换驱动”以及近期“注意力融合驱动”三大流派的批判性审视,文章清晰地标定了自己所处的学术坐标:吸取伪点云的显式几何优势,借用 Transformer 的强大全局表征能力,同时填补了过往研究在“深度噪声抑制”与“跨模态特征微调”上的巨大空白。
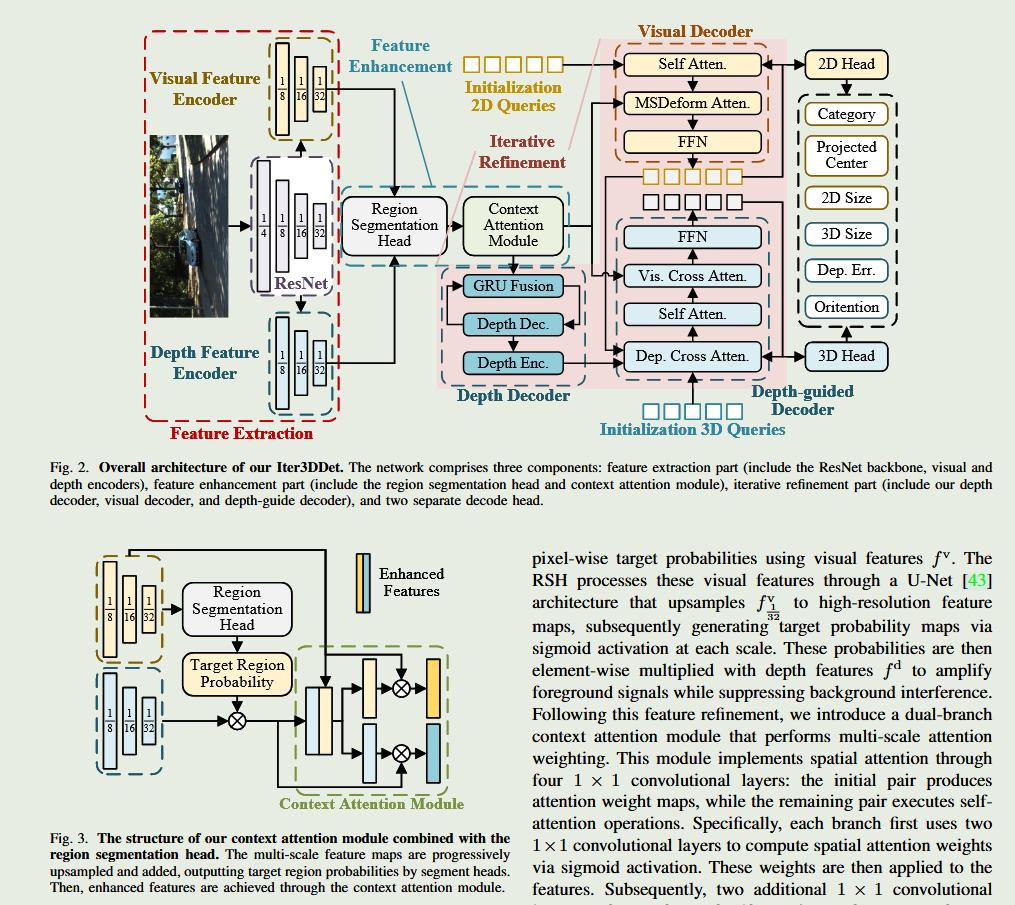
3. 核心重构:深度引导与迭代精细化方法论 (Methodology)
-
关键点 (Key Points):
-
发力点 1:特征表达与几何约束端(深度精炼管线)。 这是消除噪声的物理地基。网络首先通过一个极具创新性的多分支网络获取深度。其中一个分支利用联合图像分割掩码(Joint Image Segmentation)精确界定出前景目标(如汽车)的像素边界;另一个分支施加严格的几何约束预测该区域的初始深度值。为了防止“盲目自信”,该模块同时输出一个深度预测的置信度度量(Confidence Measure)。随后,通过场景级深度融合,将目标从背景中剥离并锚定 。紧接着,网络启动了最为核心的长尾噪声抑制器——引入经过高斯函数归一化(Gaussian function normalized)的目标尺度作为强验信息(A Priori Information)。系统评估当前预测的深度与目标在 2D 图像上的投影面积是否符合真实物理世界的尺度高斯分布,从而果断切断那些荒谬的极端深度预测,最终将优化后的干净深度图反投影,生成高保真的伪激光雷达点云(Pseudo-LiDAR Point Cloud) 。
-
发力点 2:融合与损失函数端(PV-DT3D 架构)。 伪点云准备就绪后,框架的下半场正式开场。整个检测后处理可以分为两大核心阶段。第一阶段,区域提案网络(Region Proposal Networks, RPN)在三维空间中撒网,捕捉可能包含目标的候选框;同时,利用一种特殊的“提案感知体素集合抽象模块(Proposal-aware Voxel Set Abstraction Module)”提取粗粒度的体素场景特征 。第二阶段,关键点从整个点云场景中被精细采样,并连同第一阶段的体素特征,一起被送入点-体素双 Transformer(PV-DT3D)编码器-解码器架构。在这里,点层级的 Transformer 负责挖掘局部的几何锐利特征(如车辆的边缘、朝向),而通道层级的架构则捕获不同特征维度之间的上下文关联信息。通过反复的交叉注意力机制(Cross-Attention),网络不断将预测框向真实的 Ground Truth 逼近,完成对提案的迭代细化(Proposal Refinement) 。
-
-
总结 (Summary):
本章是全篇论文的“转”折点与灵魂所在。它展现了作者对 3D 视觉系统工程学的深刻洞察力。整个方法论犹如一套精密的滤水净化与提纯系统:先用“联合分割”做粗滤,再用“高斯尺度先验”做反渗透剔除长尾杂质,得到纯净的伪点云;随后通过 PV-DT3D 这个双核处理器,用显微镜(Point)和广角镜(Voxel)交替观察,通过残差网络逐步微调,最终锻造出极具精度的 3D 边界框。理论架构浑然一体,极具美感。
4. 极限验证:实验设计与突破性成果 (Experiments)
-
关键点 (Key Points):
-
发力点:严苛基准下的实战检验。 为了证明框架的绝对实力,研究团队选择了自动驾驶领域历史最悠久、竞争最为惨烈且极具权威性的 KITTI 3D 对象检测基准数据集进行全面验证 。
-
在深入评估数据之前,有必要明确 KITTI 极其严苛的评估标准。该基准借鉴了 PASCAL VOC 的评估准则,采用具有 40 个召回位置(Recall Positions)的插值平均精度作为核心指标 。
-
难度级别被严格界定为三类,具体阈值参数如下表所示(深刻理解这些约束是读懂实验数据的关键):
-
| 难度等级 (Difficulty) | 核心约束条件 (Constraints) |
|---|---|
| Easy (简单) | 2D 边界框高度下限 $\ge$ 40 像素;最大遮挡级别:完全可见 (Fully visible);最大截断率 $\le$ 15% 。 |
| Moderate (中等) | 2D 边界框高度下限 $\ge$ 25 像素;最大遮挡级别:部分遮挡 (Partly occluded);最大截断率 $\le$ 30% 。 (注:所有公开排行榜的方法排名均以此项得分为决定性依据)。 |
| Hard (困难) | 2D 边界框高度下限 $\ge$ 25 像素;最大遮挡级别:极难辨认 (Difficult to see);最大截断率 $\le$ 50% 。 |
-
对于汽车类(Car),评估要求预测的 3D 边界框与真实框的 3D 交并比(IoU)必须达到极其苛刻的 70% 才能算作检测成功 。
-
压倒性的性能增益:经过大量且深入的对比实验,引入深度引导迭代融合机制的框架展现出了恐怖的性能统治力。在 KITTI 验证子集(Validation Subset)上,相较于当时最顶尖的各种 SOTA(State-of-the-Art)方法,该框架在 Easy 难度和 Hard 难度上的检测精度分别实现了惊人的 +12.37% 和 +5.34% 的巨大提升。即便在极其严苛的 KITTI 测试集(Test Set)官方盲测中,该模型也毫不逊色,在 Easy 和 Hard 设置下分别获得了 +5.1% 和 +1.76% 的绝对性能超越 。
| 数据集划分 | 对比基准 | Easy 提升 (AP) | Hard 提升 (AP) | 性能解析 |
|---|---|---|---|---|
| KITTI 验证集 | SOTA 竞争者 | +12.37% | +5.34% | 在已知数据分布下,高斯尺度先验彻底消灭了长尾噪声,带来了跨代际的精度跃升 。 |
| KITTI 测试集 | 官方 Leaderboard | +5.1% | +1.76% | 在面对大量未见的复杂遮挡场景时,PV-DT3D 的迭代微调展现了卓越的泛化鲁棒性 。 |
-
进一步的细粒度指标表明,在 平均朝向相似度(Average Orientation Similarity, AOS)和方向相似度(OS)上,该框架能够极度精确地回归车辆的偏航角,这对于自动驾驶轨迹预测至关重要 。
-
总结 (Summary):
实验部分完成了铿锵有力的“合”。面对动辄导致传统单目网络崩溃的深度模糊与部分遮挡挑战,Iter3DDet 在排行榜上的突破性数据,是对其方法论章节中最强有力的辩护。超过 12% 的验证集涨幅不仅证明了该算法在工程上的有效性,更宣告了通过“联合先验约束+点体素双路注意力迭代”这一范式,单目视觉方案在追赶 LiDAR 精度的漫漫长夜中,看到了一丝破晓的曙光。
⚖️ 四、 专家级锐评与启示 (Critical Evaluation & Future Work)
硬核优势 (Strengths)
-
哲学层面的“容错与救赎”机制:在过去五年的单目 3D 检测混战中,绝大多数学者陷入了一个技术执念:试图设计一种极其完美的单目深度估计网络来一劳永逸地解决深度缺失。然而,受限于透视投影的物理本质,这注定是徒劳的。本论文最大的闪光点,在于它拥有一种极具工程智慧的“妥协与救赎哲学”——它大方地承认了深度估计必然存在的高方差与不确定性,并首创性地利用高斯归一化的目标尺度先验,作为一道“安全网”来兜底并修正这些长尾噪声 。这种在概率空间中用先验常识强行扭转物理偏差的思路,极其优雅且极具现实意义。
-
多模态表征融合的集大成者:PV-DT3D 架构的设计展现了作者极其深厚的网络工程功底。它并未盲目追求全 Transformer 化,而是精准把握了 3D 点云的固有属性。通过“体素(Voxel)”抓取粗略的全局场景提案以保证效率,通过“点(Point)”在 Transformer 内部进行极高分辨率的空间与通道注意力交互以雕琢边界 。这种“宏观感知+微观微调”的设计,是计算机视觉与 3D 点云处理逻辑的一次教科书级别的联姻。
潜在局限 (Weaknesses/Limitations)
-
计算复杂度与实时性部署的天然鸿沟:虽然报告中并未详细给出车端实际运行的推理延迟(Latency),但按照常理推演,这一极其庞杂的级联架构在落地时将面临巨大挑战。首先是单目深度图的密集预测,其次是昂贵的点云反投影算子,最后还要让庞大的点云在双分支 Transformer 中经历多轮的迭代前向传播(Iterative Forward Pass)。在高度要求实时响应(通常要求延迟 $\le$ 100ms 以内)的高阶自动驾驶系统中,这种以牺牲计算密度换取精度的“大力出奇迹”模式,在边缘算力平台(Edge Devices)上可能极难达到 30 FPS 的流畅运行标准 。
-
对前端 2D 语义分割的高危依赖:该框架在深度提纯阶段极其依赖于联合图像分割的精准掩码来分离前景目标与背景 。这就埋下了一个定时炸弹:如果在暴雨、暗夜逆光或是遇到了网络未曾见过的罕见车型(即 Out-of-Distribution 样本),前端的 2D 分割网络一旦出现漏检或掩码碎裂,后续的几何深度约束和尺度先验将瞬间失去目标焦点。这种由“串联管线”带来的错误级联放大效应(Error Cascading),是所有伪激光雷达方法的通病。
后续研究方向 (Future Directions)
对于力图在该赛道继续深耕的研究者与工程师,基于本文的逻辑推演,提出以下两条极具颠覆潜力的未来探索路径:
-
时空四维连续迭代(Spatiotemporal 4D Continuous Iteration):本文证明了在“单张静态图片(空域)”中进行多次网络迭代可以不断逼近真实的三维坐标。然而,真实的驾驶场景是连续流动的视频。正如该作者团队此前在 TCSVT 上发表的另一项针对室外环境的多帧单目深度估计工作(IterDepth)所揭示的:利用 PoseCNN 计算相机位姿,并通过提取连续帧之间的 3D 成本体积(Cost Volume)来进行残差微调,可以获得压倒性的精度与极高的运行效率(比 DepthFormer 快 7 倍) 。未来完全可以将这种时序关联的门控循环深度融合单元(Gated Recurrent Depth Fusion Unit)引入到现有的 PV-DT3D 中,将 3D 边界框的迭代从“单帧空间死磕”升级为“跨帧时空平滑”,从而以极低的算力代价化解短暂的极端遮挡危机。
-
BEV(鸟瞰图)原生的端到端隐式深度感知(BEV-Native Implicit Depth):尽管高保真伪点云极大地提升了检测精度,但这种“先生成显式 3D 几何,再用 3D 网络去降维处理”的流程依然繁琐。随着新一代鸟瞰图(Bird Eye View)感知范式的崛起,未来的迭代融合网络可以尝试直接摒弃显式点云的生成步骤。通过将 2D 图像特征与预测出的概率性深度分布直接提升投影到 BEV 网格中(即将深度 Z 轴转化为 2D 卷积的特征通道进行降维打击处理 ),并在 BEV 空间内部利用 Transformer 持续进行基于查询(Query-based)的 3D 属性自适应微调。这种方案不仅能最大程度保留真实物体的物理尺寸先验,更能从架构底层规避掉繁重的点云算子,实现精度与毫秒级延迟的终极平衡。
🏷️ 五、 知识库标签 (Tags)
#单目3D目标检测 #伪激光雷达优化 #双分支Transformer #深度估计与融合 #长尾噪声抑制 #自动驾驶视觉感知