DIGGING INTO OUTPUT REPRESENTATION FOR MONOCULAR 3D OBJECT DETECTION

🏛️ 会议期刊:ICLR
📅 发表年份:2022
💻 开源代码:GitHub 链接
📄 论文题目:DIGGING INTO OUTPUT REPRESENTATION FOR MONOCULAR 3D OBJECT DETECTION
0. 一句话总结 (TL;DR)
(这篇论文用什么方法,解决了什么问题,达到了什么效果)
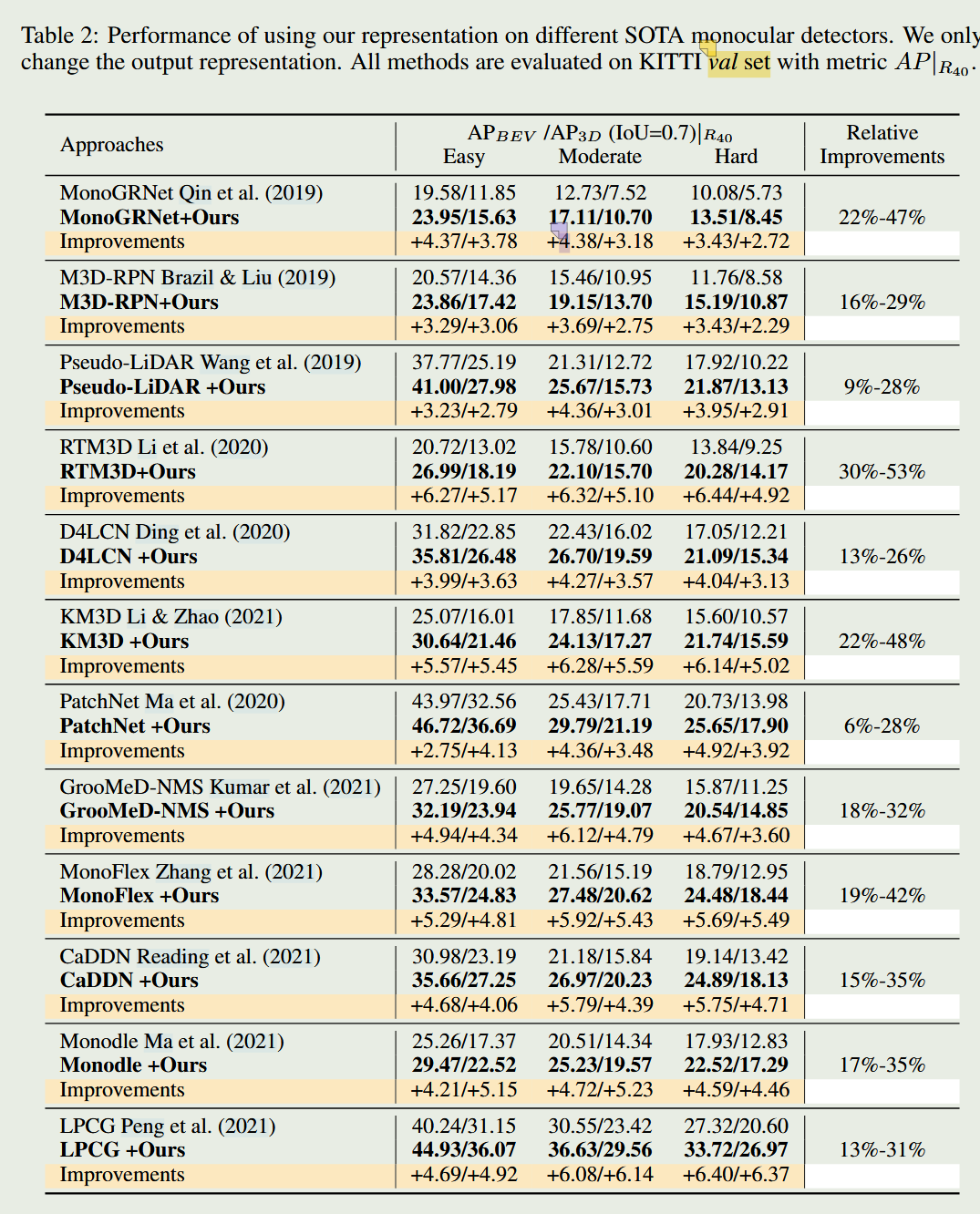
这篇论文提出将单目3D检测的输出形式从“单一且固定的离散3D边界框”重新构建为“基于深度的连续空间概率分布”。它解决了一张2D图像向3D推理时由于“维度鸿沟(Dimension Gap)”带来的深度估计极度不确定的问题。通过这种不确定性建模与沿深度的多次采样,在不改变原有网络架构的前提下,使得 12 个当时的 SOTA 模型在 KITTI 数据集上的 Average Precision (AP) 获得了约 20% 的惊人相对提升。
1. 动机与问题 (Motivation)
(现有的单目3D检测有什么痛点?)
目前的单目3D检测面临一个天然的物理限制:维度鸿沟 (Dimension Gap)。
-
信息不对等导致误差放大: 模型的输入是低维的(2D像素),但需要输出高维信息(3D坐标和体积)。这种缺失深度的病态设定,导致深度估计的误差存在一个极高的理论下界,并且这个误差会随着物体距离的增加呈二次方或指数级急剧放大。
-
现有表示方法过于“武断”: 绝大多数现有方法(包括之前的 SOTA)在输出时,都只给出一个绝对离散的、确定的 3D 预测框。但在深度极度不确定的情况下(比如 60 米外的车),给出一个“死板”的绝对坐标是非常不合理的,它完全掩盖了预测结果本身包含的巨大方差。
2. 核心方法 (Method)
(具体怎么做的?比如额外辅助模型是怎么引入的?数据增强的具体流程是什么?)
这篇论文的方法非常轻量,它完全没有引入庞大的额外辅助网络,也没有设计复杂的数据增强流程,而是纯粹在**输出端(Output Representation)**的后处理上做文章,具体分为两步:
-
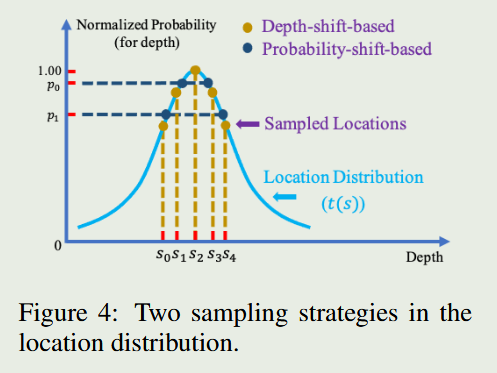
将离散输出转化为概率分布 (Distribution Transformation): 作者将原本预测出的单一深度值,转换成一个服从正态分布的“概率云”。距离相机越远的物体,其对应的正态分布的标准差(方差)就越大,以此来数学化地表达“距离越远越测不准”的物理直觉。 2.
-
基于分布的密集采样 (Sampling Mechanism): 在得到这个空间概率分布后,模型不再只输出那唯一的预测框。相反,它会沿着深度方向,根据概率分布进行多次采样,生成一系列附带不同置信度(Confidence-aware)的候选预测框。这就好比撒网,用多个带有概率的假设去覆盖真实的物体位置。
3. 实验与启发 (Experiments & Takeaways)
(在 KITTI 上涨点了多少?对我自己的研究有什么可借鉴的?)
效果极度显著。作者将这一输出表示方法作为“即插即用”的模块套用在 12 个单目3D探测器上,在推理耗时增加极小的情况下,使得它们的平均精度(AP)持续且稳定地获得了约 20% 的相对提升。
研究借鉴意义 (Takeaways):
-
不确定性建模 (Uncertainty Modeling) 是个绝佳的切入点: 在单目这种先天缺乏深度信息的任务中,不要强求模型输出绝对精准的回归值。学会让模型预测出“它的不确定度(方差)”,并利用这种不确定度来指导生成更多的假设或参与 Loss 的加权,是一种非常有价值的研究思路。
-
警惕“数值技巧 (Numerical Trick)”与评测机制的博弈: 严格来说,这篇论文更像是一个极其聪明的数值技巧。它利用了多点采样来“暴力覆盖”真实框,从而在 KITTI 的 AP 计算规则下大幅提高了 Recall 从而刷高分数。在后续的研究中,这种思路可以借鉴作为提分手段,但在写 Motivation 时,必须要自圆其说(例如解释清楚这些大量重叠的候选框在自动驾驶真实的下游 Tracking 模块中该如何被过滤和使用),否则容易受到 Reviewer 的质疑。